

.png)
Every minute a critical database sits unreachable, an organization loses an average of $7,900. For Fortune 500 companies, that number can breach the million-dollar mark within an hour. Yet most data leaders are making replication decisions based on conventional wisdom, not architectural reality.
This guide cuts through the noise. Whether you are evaluating database replication strategies for the first time, reassessing an existing setup for cloud readiness, or comparing RDS replication configurations before a migration, what follows is the most complete, business-grounded reference you will find in one place.
We cover every major replication method, the tools shaping the market in 2026, RDS-specific architecture patterns, and the questions that should drive every architecture conversation. No vendor pitch, no filler: just the substance that turns good data leaders into great ones.

Sources: Integrate.io (2026); Business Research Insights (2026); Integrate.io (2026)
What database replication actually is (and what it is not)
Database replication is the process of copying and continuously synchronizing data from a source database, often called the primary or leader, to one or more target databases, called replicas, standby instances, or read nodes. The operational goal is simple: ensure that a live, accurate copy of your data exists somewhere else, so that failures, performance spikes, and geographic distance never become business problems.
What replication is not: it is not a backup. A backup is a point-in-time snapshot you restore after something goes wrong. A replica is a continuously updated copy that can take over with minimal or zero data loss. The distinction matters enormously when you are defining recovery point objectives (RPO) and recovery time objectives (RTO) for a production system.
Key distinction for decision makers
If your RTO is measured in seconds and your RPO is near-zero, replication is not optional. It is the architecture. Backup alone cannot meet those thresholds.
The replication engine works by monitoring the source for changes, capturing those changes, transmitting them over the network, and applying them to the target. The mechanism used to capture changes, the timing of transmission, and the consistency model applied at the target are the three variables that separate one replication strategy from another.

The core database replication strategies: a structured breakdown
Replication strategies are not a menu where you pick one and forget the rest. They are architectural layers that experienced data teams combine. Here is a complete breakdown of every major strategy, what it solves, and where it falls short.
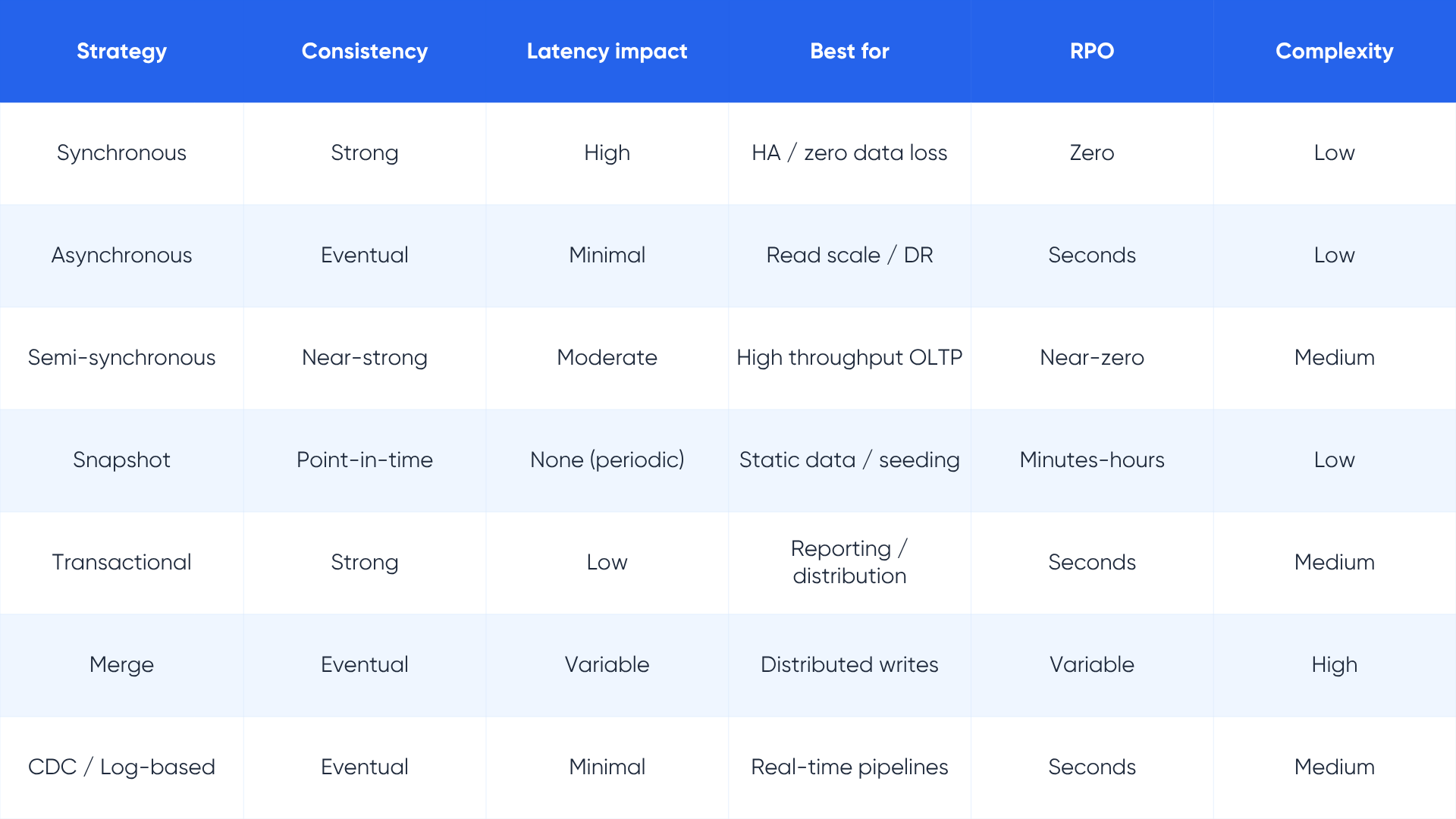
1. Synchronous replication
In synchronous replication, a write to the primary database is not confirmed to the application until the same write has been committed to the replica. Both nodes must acknowledge success before the transaction completes. This guarantees zero data loss and strong consistency at all times.
Use cases: Financial transaction systems, healthcare records, any workload where losing even a single committed transaction is unacceptable. Amazon RDS Multi-AZ deployments use synchronous replication, ensuring automatic failover with no data loss when a primary instance fails.
Trade-offs: Write latency increases because every transaction must round-trip to the replica before completing. This is why synchronous replication is typically constrained to the same region or datacenter. Spanning continents synchronously would make most applications unusable.
2. Asynchronous replication
The primary writes data and immediately confirms success to the application. The replica receives the changes in the background, after the fact. This means the replica may lag behind the primary by milliseconds to seconds, introducing eventual consistency.
Use cases: Read-heavy workloads, business intelligence pipelines, analytics offloading, and cross-region disaster recovery where some replication lag is acceptable. Amazon RDS Read Replicas operate asynchronously, distributing read traffic across up to 15 replicas without impacting primary write performance.
Trade-offs: Replication lag is the inherent risk. During a failover, you may lose the data that was in flight between the primary and replica. This is the core engineering tension in any asynchronous architecture.
3. Semi-synchronous replication
A middle ground: the primary waits for at least one replica to acknowledge receipt of the transaction log before confirming success, but does not wait for the full commit on the replica. Used by MySQL semi-sync replication, this approach improves data durability over pure async while reducing the write latency penalty of full synchronous replication.
Use cases: High-throughput transactional applications where some replication lag is tolerable but complete data loss during failover is not. Common in e-commerce and SaaS platforms.
4. Snapshot replication
A complete copy of the source database is taken at a specific point in time and replicated to the target. Subsequent snapshots replace or are merged with the previous copy. This is the simplest form of replication and the foundation on which most CDC and log-based systems perform their initial baseline synchronization.
Use cases: Static or slowly changing reference data, initial seeding of replicas, regulatory archiving. Not suited for real-time operational continuity.
5. Transactional replication
Changes are captured at the transaction level: inserts, updates, and deletes are shipped to the replica in the exact order they occurred on the primary. The replica becomes a consistent, transactionally accurate copy. SQL Server's native transactional replication is the canonical example, used widely in reporting and data distribution scenarios.
Use cases: Operational reporting, data distribution to remote branch databases, and read-scale architectures for OLTP systems.
6. Merge replication
Both the primary and the replica can accept writes. Changes from both sides are periodically merged with conflict resolution logic applied when the same record has been modified in two places. This approach is architecturally complex but necessary for distributed write scenarios.
Use cases: Field operations with intermittent connectivity, mobile applications that sync data when online, multi-site architectures where each location writes locally.
7. Change data capture (CDC) replication
CDC systems read the database transaction log directly, capturing only the rows that changed rather than scanning entire tables. This is the highest-performance, lowest-impact approach to continuous replication and has become the standard for real-time data pipelines feeding analytics platforms, event streams, and data lakehouses.
Tools like Debezium, AWS DMS (in CDC mode), Oracle GoldenGate, and Fivetran all leverage log-based CDC. Modern CDC systems can process thousands of events per second and feed targets ranging from Kafka topics to cloud data warehouses with latency measured in seconds.
Industry note: CDC is not just a replication technique. When paired with a streaming platform such as Apache Kafka, it becomes the backbone of event-driven architectures. A single CDC pipeline can simultaneously feed a data warehouse, a search index, a cache layer, and a downstream microservice.
Strategy comparison: choosing the right approach for your architecture
RDS database replication: what every AWS user needs to know
Amazon RDS is the world's most widely deployed managed relational database service, and understanding its replication architecture is non-negotiable for any business operating in AWS. RDS offers three distinct replication configurations, each serving a different operational objective.
Multi-AZ deployments: built for high availability
Multi-AZ is RDS's primary high availability mechanism. When you enable Multi-AZ, AWS automatically provides a synchronous standby replica in a different Availability Zone within the same region. Every write to the primary is committed to the standby before the application receives confirmation. If the primary fails, AWS performs an automatic failover in 60 to 120 seconds, with no changes required to connection strings.
Architecture note
Multi-AZ standby replicas do not serve read traffic. They exist solely for failover durability. If you need to offload reads, you need Read Replicas in addition to Multi-AZ, not instead of it.
Multi-AZ is supported across Aurora (MySQL and PostgreSQL compatible), MariaDB, MySQL, Oracle, PostgreSQL, SQL Server, and DB2 (available from 2025). The synchronous nature means there is zero data loss on failover, but write latency is modestly higher because each transaction must traverse two Availability Zones.
Read replicas: built for scale
Read Replicas use asynchronous replication to create one or more read-only copies of your primary instance. They distribute read traffic, dramatically reducing load on the primary during analytics, reporting, and business intelligence workloads. RDS for MySQL, MariaDB, PostgreSQL, and SQL Server support up to 15 Read Replicas per primary.
Read Replicas can be deployed within the same Availability Zone, across Availability Zones, or across regions. Cross-region Read Replicas introduce additional latency but provide geographic redundancy and can be promoted to standalone instances in a disaster recovery scenario.
Replication lag is the critical variable. Because replication is asynchronous, a Read Replica may return stale data. For read workloads where eventual consistency is acceptable (analytics, reporting, dashboards), this is a non-issue. For workloads requiring the latest committed data, reads should go to the primary or a Multi-AZ primary.
Cross-region replication: built for global resilience
AWS supports cross-region replication via Cross-Region Read Replicas and Aurora Global Database. Aurora Global Database replicates data across up to five secondary regions with typical replication lag under one second and can perform a managed cross-region failover in under a minute. For businesses operating globally or with regulatory requirements to maintain data sovereignty in specific geographies, this architecture is the foundation layer.
Database replication tools: the market in 2026
The data replication software market was valued at approximately $6.28 billion in 2026 and is on track to reach $12.54 billion by 2035, growing at a CAGR of 7.5%. Hybrid deployments are the fastest-growing segment, expanding at a CAGR of 16.8% as enterprises pursue multi-cloud flexibility.
Here is a structured overview of the leading tools across different deployment contexts.
Enterprise-grade platforms

Cloud-native and managed services
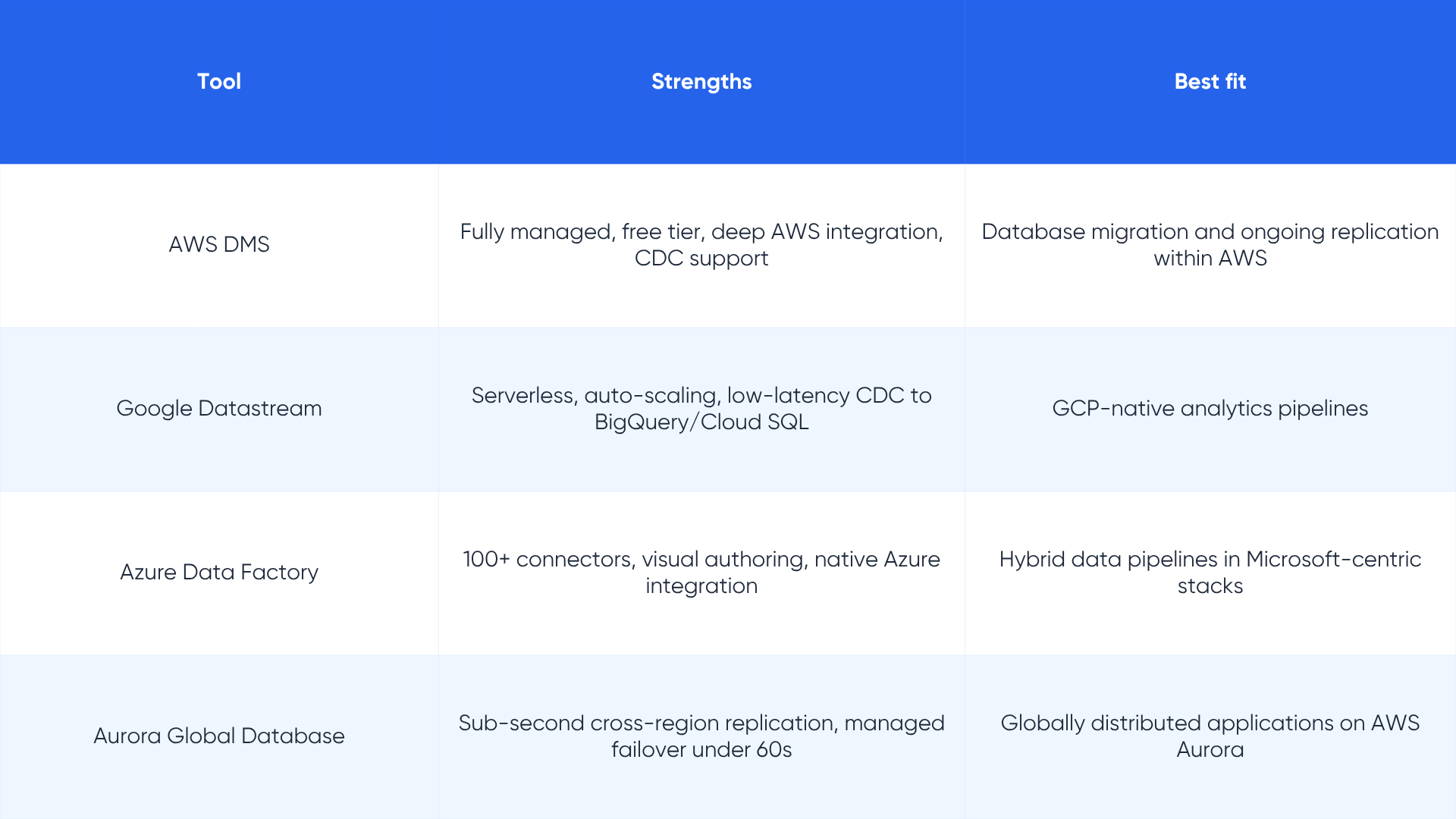
Database replication techniques: the implementation layer
Knowing which strategy to use is the first decision. Knowing how to implement it is the second. The following techniques apply across strategies and tools, and represent the practical craft of production-grade replication.
Log-based capture
Reading the database transaction log (WAL in PostgreSQL, binlog in MySQL, redo log in Oracle) rather than polling tables is the gold standard for high-performance, low-impact replication. Log-based capture does not require triggers, agents, or application changes. It captures every committed change including deletes and schema updates, which poll-based approaches often miss.
Change data capture with filtering
Not every table needs to be replicated. Well-designed CDC pipelines include table-level and column-level filters that reduce replication volume, protect sensitive columns from leaving the primary system, and eliminate the overhead of replicating audit or log tables that have no value in the target.
Active-active replication
Both the primary and one or more replicas accept writes simultaneously. Changes are bidirectionally synchronized with conflict resolution logic applied when the same row is updated in two places concurrently. This architecture is significantly more complex than active-passive designs but is necessary for globally distributed applications with local write requirements.
Architecture caution
Active-active replication is often over-engineered into situations that do not require it. If your write traffic can be routed to a single region, active-passive with fast failover is almost always the right choice. Reserve active-active for genuine multi-site write requirements.
Cascaded replication
A replica can itself serve as the source for further downstream replicas. This fan-out pattern reduces load on the primary while distributing data to multiple consumers: a data warehouse, a search platform, a regional read endpoint, and a compliance archive can all subscribe to different tiers of the same replication chain.
Batch size and compression optimization
In high-throughput environments, batch sizes for transactional replication significantly impact performance. Research benchmarks show optimal performance with batches of 200 to 500 transactions for SQL Server distribution agents. Modern compression algorithms like LZ4 and Zstd achieve compression ratios of 89 to 97 percent at speeds orders of magnitude faster than gzip, making them essential for wide-area network replication.
Industrial realities: how leading organizations are using replication
The architecture choices that look reasonable in a whitepaper often look very different under production load. Here are real patterns from organizations operating at scale.
Financial services: zero tolerance for data loss
Banks and payment processors use synchronous Multi-AZ replication as the baseline and layer cross-region CDC pipelines on top for analytics and regulatory reporting. The primary database runs active-passive with sub-minute failover. The analytics warehouse receives CDC events with seconds of lag. Compliance archives receive encrypted snapshots hourly. This is three distinct replication strategies running in parallel, each serving a different consumer with different consistency and latency requirements.
E-commerce: read scale during peak load
Shopify's MySQL 8 infrastructure handled approximately 3 million writes per second during Black Friday 2026 and sustained a 10:1 read-to-write ratio. At that scale, directing all reads to the primary is not viable. Production e-commerce architectures route application reads to read replicas while reserving the primary for writes, cache-miss reads, and inventory operations that require absolute consistency.
Global SaaS: geographic distribution without active-active complexity
Most global SaaS platforms do not use active-active replication despite serving users in dozens of countries. Instead, they use asynchronous cross-region replicas for reading and direct all writes to a primary region, accepting the latency trade-off for writes in exchange for dramatically simpler conflict resolution. Aurora Global Database has made this pattern accessible to organizations that previously could not afford the engineering complexity of global replication.
Healthcare: compliance-driven architecture
Healthcare organizations must meet HIPAA requirements for data availability and integrity. In practice, this means synchronous replication for patient records within the primary region, encrypted cross-region replicas for business continuity, and point-in-time recovery capabilities with retention periods defined by regulatory mandate. Tools that cannot prove end-to-end encryption in transit and at rest are disqualified regardless of performance.

How to choose the right database replication strategy: a decision framework
The question of which replication strategy to use cannot be answered in the abstract. It depends on four variables that your team must define before an architect touches a configuration file.
Define your RPO and RTO
Recovery Point Objective is the maximum acceptable data loss expressed in time. Recovery Time Objective is the maximum acceptable downtime. RPO near zero and RTO under 60 seconds points to synchronous replication with automated failover. RPO of minutes and RTO of hours opens the door to simpler, lower-cost approaches. Every replication architecture discussion should begin here.
Map your read-to-write ratio
Read-heavy workloads benefit from read replicas offloading query traffic from the primary. Write-heavy workloads may see no benefit from read replicas and may actually require sharding or database partitioning instead. Understanding your workload profile before choosing a replication topology is the single most common thing organizations skip.
Assess your consistency requirements by workload
Not all queries in a production system need the freshest data. Analytics dashboards that refresh every 10 minutes have very different consistency requirements than a payment confirmation page. Well-designed systems route different queries to different replicas based on staleness tolerance, optimizing both cost and performance.
Consider your regulatory and compliance environment
GDPR, HIPAA, SOC 2, and sector-specific regulations often dictate where data can replicate, how it must be encrypted, and how long it must be retained. Cross-region replication may be legally constrained for certain data categories. Compliance should be a first-class input to your replication architecture, not an afterthought you accommodate at the end.
For teams evaluating cloud data infrastructure options
Understanding how replication fits into your broader data architecture is critical. LakeStack's data engineering services help organizations design replication pipelines that align with both technical requirements and business continuity objectives. See our data architecture services page for more.
Common pitfalls that undermine replication strategies
Even well-designed replication architectures fail in predictable ways. These are the patterns worth building defenses against.
Treating replication lag as a background concern
Replication lag is not a fixed number. It spikes during heavy write bursts, network congestion, or when a replica falls behind and must catch up. Applications that read from replicas without accounting for lag can make decisions based on stale state. Monitor replication lag continuously, not just at setup time.
Never testing failover in production conditions
A replication setup that has never been failed over is not a replication setup. It is a hypothesis. Database performance audits that include failover testing reduce downtime by 40% on a quarterly basis. Schedule and run failover drills under production-realistic load before you need them.
Replicating everything without filtering
Blindly replicating every table and column consumes network bandwidth, inflates storage costs, and can create compliance exposure when sensitive columns land in analytics systems that were never designed to hold them. Every replication pipeline should have an explicit inclusion list, not an exclusion-based free-for-all.
Conflating migration with ongoing replication
AWS DMS, for example, is an excellent migration tool. It is not the right long-term replication platform for production analytics pipelines in most architectures. Using a tool designed for one-time migration as a perpetual replication mechanism introduces operational complexity and cost inefficiency that compounds over time. Choose tools designed for the job at hand.
The convergence of replication and the modern data stack
Database replication does not exist in isolation anymore. In a modern data architecture, it is the mechanism that connects transactional systems to analytics platforms, event streams, machine learning pipelines, and real-time operational dashboards.
CDC-based replication feeding Apache Kafka is the standard pattern for event-driven architectures. Kafka topics become the single source of truth for downstream consumers including data warehouses such as Snowflake and BigQuery, search platforms such as Elasticsearch, and AI feature stores. The primary database is no longer the only system that needs your data. It is the originating point in a data flow that spans multiple systems.
This convergence has two important implications for data leaders. First, replication tooling must be evaluated not just on database-to-database capability but on its ability to participate in a broader streaming ecosystem. Second, the team designing replication strategy and the team designing data pipelines need to be in the same room. Decisions made in isolation create brittle architectures.
Teams exploring how replication connects to data lakehouse architectures and real-time analytics pipelines can explore LakeStack's data pipeline design resources for patterns that bridge operational databases and analytical systems.
What to take into your next architecture conversation
Database replication is one of the most consequential architectural decisions a data organization makes. The wrong strategy can mean lost transactions during a failover, analytics that are hours stale, compliance exposure from unencrypted cross-region data movement, or replication costs that scale faster than the business.
The right strategy aligns with your specific RPO, RTO, consistency requirements, and regulatory environment. It combines multiple approaches: synchronous for high availability within a region, asynchronous for read scale and cross-region DR, and CDC for feeding the downstream data ecosystem.
No single replication tool serves every use case. The vendors that say otherwise are selling you something. Use managed services where they reduce operational burden without introducing vendor lock-in risk, and evaluate open-source tools where control and cost matter more.
Key takeaways
- Database downtime costs organizations an average of $7,900 per minute. Replication is the architecture that prevents it.
- Synchronous replication guarantees zero data loss but increases write latency. Asynchronous replication prioritizes performance and read scale at the cost of possible lag.
- RDS Multi-AZ provides synchronous HA within a region. Read Replicas provide asynchronous read scales across up to 15 copies. Cross-region replication extends resilience globally.
- CDC and log-based replication are the industry standards for real-time pipelines feeding analytics, streaming, and data lakehouse platforms.
- The data replication software market is growing at 7.5% annually, driven by hybrid cloud adoption, ransomware threats, and real-time analytics demand.
- Always define RPO and RTO before selecting a replication strategy. Architecture follows requirements, not the other way around.
- Test failover under realistic load. A replication setup that has never been tested is an untested hypothesis.
Sources and citations
[1] Integrate.io. Database Replication Speed Metrics: 40 Statistics Every IT Leader Should Know in 2026. integrate.io/blog/database-replication-speed-metrics/
[2] Business Research Insights. Database Layer Data Replication Software Market: Size and Trend 2035. Report ID 113329, March 2026.
[3] Market Insights Research. Data Replication Software Market Size. 2024-2035 Forecast, March 2025.
[4] N-able. The True Cost of Downtime: Why Cyber Resilience Matters. n-able.com/blog/true-cost-of-downtime, November 2025.
[5] Amazon Web Services. Amazon RDS Read Replicas. aws.amazon.com/rds/features/read-replicas/. Accessed April 2026.
[6] Amazon Web Services. Working with DB Instance Read Replicas. docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_ReadRepl.html
[7] KodeKloud. AWS RDS Replication Types Introduction. notes.kodekloud.com. Accessed April 2026.
[8] Streamkap. Top 12 Database Replication Tools for 2025. streamkap.com/resources-and-guides/database-replication-tools
[9] Airbyte. 10 Best Data Replication Tools in 2026. airbyte.com/top-etl-tools-for-sources/top-data-replication-tools
[10] Pure Storage Blog (Everpure). Synchronous Replication vs Asynchronous Replication. blog.purestorage.com. January 2026.
[11] Firefly. Implementing Data Replication Strategies for Disaster Recovery in the Cloud. firefly.ai/academy
[12] Data Horizzon Research. Data Replication Market Size, Growth, Share and Analysis Report 2033. datahorizzonresearch.com
[13] Stacksync. 9 Data Replication Tools You Need in 2026. stacksync.com/blog, March 2026.
[14] Quest Software. SharePlex Database Replication Software. quest.com/products/shareplex
About LakeStack
LakeStack helps businesses design, build, and operate data infrastructure that scales with confidence. From database architecture and replication pipelines to data lakehouse design and cloud migration, our engineering teams work alongside yours to solve the hard problems. Explore our services at lakestack.com.



