

Critical data still arrives as files. Your data platform must be ready for it.
LakeStack file replication securely syncs file data from on-prem systems, cloud storage, and partner exchanges into your AWS data foundation for analytics, governance, and AI.


Files discovered and ingested the moment they arrive, no manual uploads or scheduled scripts
Every file tracked with source, timestamp, format, and schema from the moment of ingestion
File arrival automatically triggers transformation and processing workflows downstream
File-based data is everywhere, and notoriously hard to manage
Despite the rise of APIs and streaming systems, files remain a critical data source in virtually every enterprise. The problem is that file ingestion is almost always manual, brittle, and ungoverned.
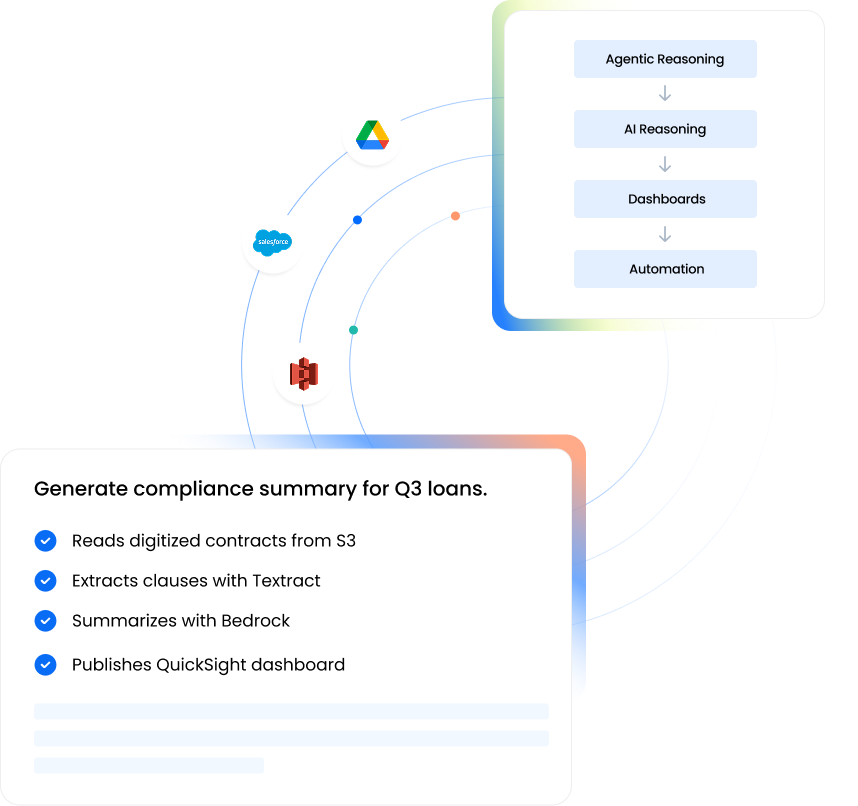
Detect, transfer, govern, process, automatically
LakeStack monitors file sources continuously, transfers files securely into the AWS-based data lake, captures full metadata and lineage, and triggers downstream processing, all without manual intervention.
LakeStack monitors on-prem file systems, cloud storage, SFTP servers, and partner exchanges for new or updated files using scans, events, or webhooks.
Files are transferred securely into the LakeStack environment via SFTP ingestion, secure API uploads, or cloud object storage replication, ensuring reliable, encrypted transmission.
Transferred files are stored in the LakeStack S3-based data lake in a structured folder hierarchy, organized by source system, dataset type, and time-based partitioning for efficient downstream processing.
During ingestion, metadata is recorded for every file: source system, ingestion timestamp, file format, file size, and schema detection results, registered in the LakeStack governance layer.
LakeStack performs automatic schema inference on structured and semi-structured files, detecting column types and structures without requiring manual configuration.
File arrival triggers downstream processing pipelines via AWS Lambda and EventBridge, validating files, running transformations, and preparing data for analytics and AI workloads.
Every major file format, handled automatically
LakeStack file replication handles the full range of structured and semi-structured file formats produced by operational systems, legacy platforms, and partner exchanges.
Built on native AWS services for scale, security, and reliability
LakeStack file replication pipelines leverage purpose-built AWS services to ensure that file-based data is transferred, stored, and processed reliably at any scale.

Primary storage layer for all replicated files. Scalable, durable, and natively integrated with LakeStack transformation and analytics pipelines.

High-speed, secure transfer of files from on-premise systems and enterprise file shares into S3. Handles large-volume replication automatically.

Secure file ingestion from partners and external systems via SFTP, FTPS, and FTP, without exposing internal infrastructure.

Event-driven functions that trigger on file arrival, validating files, capturing metadata, and initiating transformation workflows immediately.

Orchestrates downstream processing across the LakeStack architecture when file arrival events are detected in S3.

Performs schema detection and initial transformation on replicated files, converting raw data into structured datasets ready for analytics and AI.
File replication built into the platform, not bolted on
Most organizations handle file ingestion with custom scripts or basic ETL tools. LakeStack integrates file replication directly into the governed data architecture, so file-based data participates in the same lifecycle as database and SaaS data.
LakeStack automatically detects and replicates files, eliminating manual uploads, scheduled scripts, and the operational overhead that comes with them.
Every replicated file is registered with metadata and lineage. File-based data is governed with the same rigor as database or SaaS-sourced data.
File arrival automatically triggers transformation and validation pipelines, moving organizations from static batch processing to event-driven data workflows.
Files enter the same governed lifecycle as all other LakeStack sources, able to be joined with database data, SaaS signals, and streaming events for unified datasets.
CSV, JSON, XML, Parquet, logs, batch exports, LakeStack handles the full range of file formats from on-premise systems, cloud storage, and partner exchanges.
File replication ensures that legacy systems exporting data as files can participate fully in modern data architectures, without rebuilding those systems.
From raw file transfers to governed operational intelligence
Reliable file replication opens up a range of capabilities that are simply unavailable when files are managed manually or through brittle scripts.
Legacy platforms that export data as files can now participate in modern analytics and AI architectures, without requiring costly system replacement or API development.
Application logs and operational event files can be replicated, transformed, and analyzed, supporting security monitoring, operational observability, and performance insights.
Ingest data shared by partners, suppliers, and ecosystem participants through secure file transfers, common in supply chain, financial services, and healthcare environments.
Files containing historical and operational data are transformed into structured datasets, directly usable for AI model training, feature engineering, and predictive analytics.
File replication in the LakeStack data lifecycle
File replication sits within the Connect and ingest layer of the LakeStack platform, ensuring that file-based data sources feed into the same governed environment as database and SaaS data.
File detection
LakeStack monitors on-premise systems, cloud buckets, and SFTP servers for new and updated files across all configured sources.
Secure transfer
Files are transferred into the LakeStack environment via SFTP, secure API, or cloud object replication, encrypted and verified in transit.
S3 lake storage
Files land in the Amazon S3-based LakeStack data lake, organized by source, type, and ingestion time for efficient downstream access.
Transformation
AWS Glue and event-driven pipelines convert raw file data into structured, queryable datasets alongside other enterprise data sources.
Governance
Metadata, lineage, and access policies enforce compliance and data quality across all replicated file data.
Intelligence & activation
Governed file data powers AI models, analytics workloads, and operational intelligence, activated back into business workflows.
Frequently asked questions
Most data sources can be connected quickly using pre-built connectors, without writing custom code. The actual setup time depends on the complexity of your source system and access permissions, but in most cases, teams can start ingesting data within hours instead of days. This removes the typical delays caused by engineering dependencies.
Yes, LakeStack supports both real-time and batch ingestion, so you can choose what fits your use case. For operational use cases like dashboards or customer workflows, real-time ingestion ensures your data stays fresh and actionable. For reporting or historical analysis, batch pipelines help optimize cost and performance without compromising reliability.
Schema changes are one of the most common reasons pipelines fail. LakeStack is designed to handle schema evolution automatically, so your pipelines continue running even when source data structures change. This reduces manual fixes, prevents data loss, and ensures your downstream systems always receive consistent data.
LakeStack includes built-in monitoring, alerting, and fault tolerance mechanisms that continuously track pipeline health. If an issue occurs, your team is notified immediately so it can be resolved before it impacts business users. This means fewer silent failures, more predictable data flows, and higher trust in your data.
No, LakeStack handles the underlying infrastructure, so your team does not have to manage pipelines, scaling, or maintenance manually. This allows your engineering and data teams to focus on building use cases and driving outcomes, instead of spending time on operational overhead.
.png)
.png)

Ready to start replicating your files?
See how LakeStack file replication brings your file-based data into your governed AWS data foundation, reliably, automatically, and with full lineage from day one.
