

One foundation. Five capabilities. Zero assembly.
LakeStack is not a stack of tools you integrate. It’s a single system where ingestion, transformation, governance, activation, and AI are already connected and already running the moment it lands in your cloud.
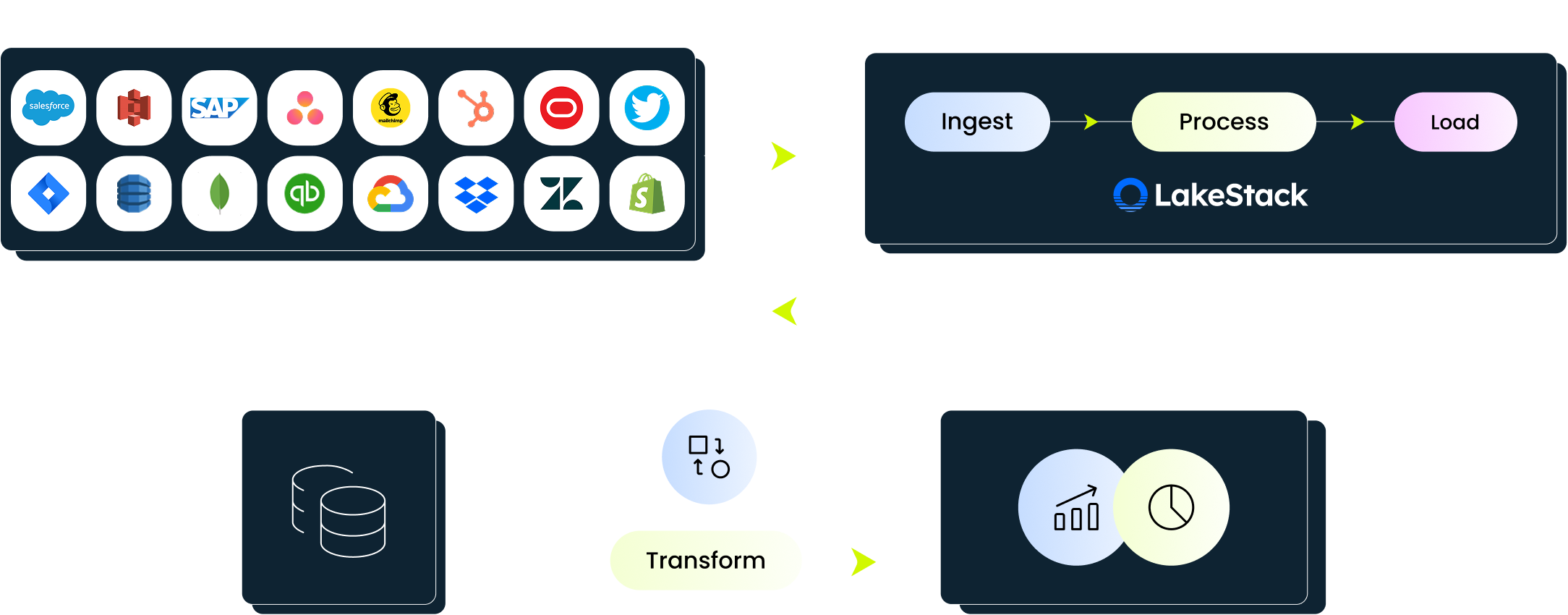

How the foundation works, end to end
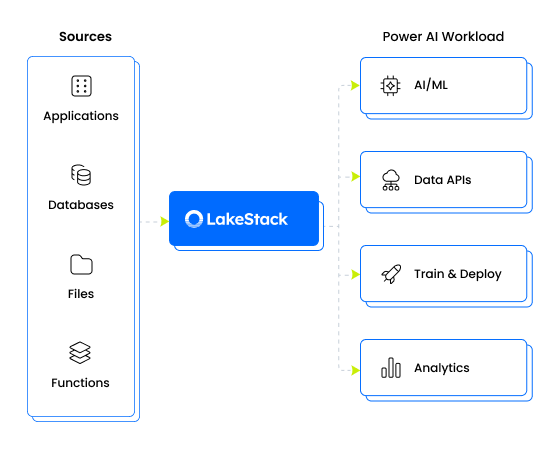
Pre-built connectors and intelligent automation eliminate the manual work of moving data from source to foundation.
- Connectors for databases (SAP, Oracle, SQL Server, Postgres, MongoDB), SaaS apps (Salesforce, HubSpot, Zendesk, Shopify), files, and APIs
- Batch, micro-batch, and real-time (CDC) ingestion modes to match any data velocity requirement
- AI-assisted schema detection handles 90-95% of field mapping automatically
Standardized patterns and automatic adaptability turn messy source data into clean, trusted datasets, without manual intervention.
- Standardized transformation patterns produce dimensional models, domain-aligned datasets, and business-logic-centralized views
- Transformations adapt automatically when upstream schemas change
- Continuous validation and data-quality rules catch issues before they reach downstream consumers
Governance isn't a layer added after the fact; it's enforced the moment data enters the foundation.
- Role-based access control, column-level masking, sensitive-field classification, and row-level policies protect data at every level
- End-to-end lineage tracks data from source to consumption across every transformation
- Audit-ready logging ensures compliance without additional tooling or retroactive effort
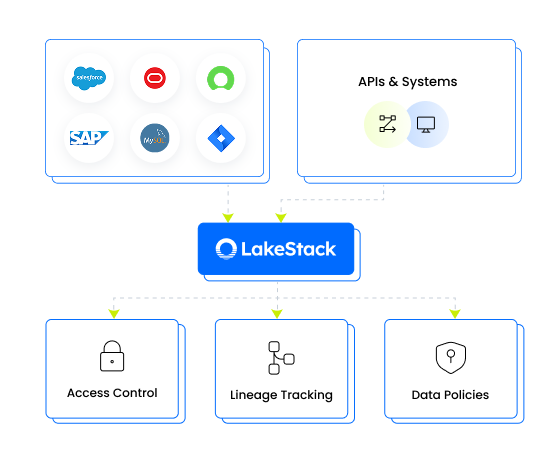
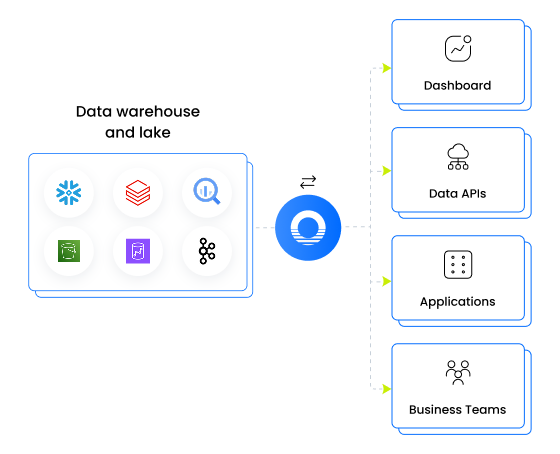
Deliver trusted datasets to every tool, team, and system - from one governed source of truth.
- Serve data to BI tools, downstream applications, internal APIs, and business teams with consistent access controls
- Reverse ETL pushes governed data back into operational systems to close the loop
- A semantic layer keeps metrics and definitions consistent wherever data is consumed
Business users get answers from trusted data without writing SQL or waiting on analysts.
- Natural language queries let users ask questions in plain English and get answers grounded in the governed foundation
- Enterprise search spans both structured and unstructured data across the entire data fabric
- Predictive models and decision-support workflows run on the same governed data layer as the rest of the platform
What customers typically see
LakeStack replaces months of engineering work with weeks of deployment and delivers ROI before most data projects have finished scoping.
One platform to make your data AI-ready
Typical SaaS stacks make you manage every layer separately so every change ripples into a multi-tool, multi-team problem. LakeStack is built as one system, so nothing falls through the cracks.
Where teams unlock value from their data
Data modernization
Replace legacy systems with a modern data foundation that reduces complexity, improves reliability, and scales with your business.
Data connectivity
Unify data across systems and sources so your teams always work with complete, up-to-date information.
AI readiness
Move from fragmented data to production-ready datasets that power real AI and machine learning use cases.
Pipeline automation
Remove manual pipeline work and keep data flowing reliably with automated ingestion, transformation, and updates.
Self-service analytics
Give business teams direct access to trusted data so they can explore, analyze, and act without engineering bottlenecks.
See it in your environment.
A 45-minute architecture review walks through your current sources, your target use cases, and how LakeStack would deploy in your cloud. No demo theater, a working session with a solution architect.
Built for data-intensive industries.

Unify EHR, lab, and claims data into a single governed foundation. Enable clinical and operational decisions without manual data prep.

Bring product, CRM, billing, and support data together. Build customer 360, retention models, and revenue insights on a single source of truth.

Connect ERP, plant systems, and sensor data into one foundation. Reduce downtime and improve cross-plant visibility with real-time insights.

Unify shipment, warehouse, and tracking data across partners. Move from delayed reports to real-time visibility and faster decisions.
.png)
.png)
.png)
Frequently asked questions
Most teams build ingestion, transformation, and access layers using multiple AWS services, but that requires designing pipelines, managing orchestration, and maintaining integrations over time. LakeStack brings these together into a pre-configured system that runs within your AWS environment. You still use AWS services, but without the overhead of stitching them together or maintaining pipelines across layers.
No. LakeStack eliminates the need for separate tools across the data lifecycle. It standardizes how data is ingested, prepared, and used within a single system, so you don’t have to manage connectors, pipelines, and activation layers independently. This reduces both complexity and ongoing maintenance effort.
LakeStack removes the need to build and maintain pipelines, connectors, and access layers. Once the system is in place, data flows continuously and is made usable across analytics, applications, and AI. This allows business teams to access and use data directly, while engineering teams can focus on higher value work instead of maintaining infrastructure.
LakeStack ensures data is structured, governed, and continuously available, which is what most AI initiatives struggle with. Instead of preparing data separately for each model or use case, AI systems can directly use the same data layer for training, retrieval, and inference. This makes it easier to move from experimentation to production without rebuilding data pipelines.
LakeStack runs entirely within your cloud environment, so your data never leaves your infrastructure. It applies consistent access controls, masking, and governance policies across analytics, applications, and AI usage. This ensures that data is not only accessible, but also secure and compliant with enterprise requirements.
See how this would work in your environment
We’ll map your current systems, data flows, and use cases, then show exactly how LakeStack would be deployed inside your AWS account.
Book an architecture review