


There is a conversation that happens inside almost every data organization at some point, usually when something breaks. Someone asks whether the team has replication configured, someone else says the database is backed up, and a third person wonders if clustering covers them. Three people, three different answers, and not one of them is wrong, exactly. They are just not talking about the same thing.
Database replication, backup, clustering, mirroring, and sharding are not interchangeable. They are not even close substitutes. Each one solves a distinct engineering problem, and choosing the wrong one for the wrong problem is how organizations end up with systems that look resilient on a diagram and collapse under the first real incident.
This guide was written for the decision makers who sit at the intersection of business and technology. You do not need to understand every line of replication configuration to make a sound architecture call. But you do need to understand what these concepts actually do, how they differ, and when to combine them. That is what this reference gives you.

Sources: N-able / ITIC (2024); Data Horizzon Research (2023); Integrate.io (2026)
Setting the stage: what database replication actually does
Before comparing replication to anything else, it helps to be precise about what it is. Database replication is the continuous, automated process of copying committed changes from a source database to one or more target databases, keeping those targets synchronized with the original in near-real-time or in real-time depending on the method chosen.
The operative word is continuous. A replica is not a frozen snapshot of yesterday's data. It is a live system that reflects the current state of the primary with some degree of latency, ranging from zero milliseconds in synchronous configurations to seconds or minutes in asynchronous ones. This live quality is what makes replication fundamentally different from most of its commonly confused alternatives.
Architecture principle
Replication solves two things: availability (what happens when a database fails) and read scalability (how many read queries a system can serve without degrading). Everything else: backup, clustering, sharding, mirroring, serves different primary goals. Knowing which problem you are solving is the first step.
The database replication process: inside the engine room
Understanding the mechanics of replication at a conceptual level helps decision makers ask better questions and spot gaps in an architecture. The process has four stages regardless of the tool or database engine involved.
Stage 1: Change capture
Every write-capable database maintains an internal transaction log, a sequential, append-only record of every committed change. PostgreSQL calls this the Write-Ahead Log or WAL. MySQL calls it the binary log or binlog. SQL Server uses the transaction log. Oracle maintains the redo log.
The replication engine monitors this log continuously. When a row is inserted, updated, or deleted, that change is first written to the log before it is applied to the data files. This is what makes the log the authoritative source for replication: it captures every committed change in the exact order it occurred, including deletions and schema modifications that polling-based approaches often miss entirely.
Stage 2: Transmission
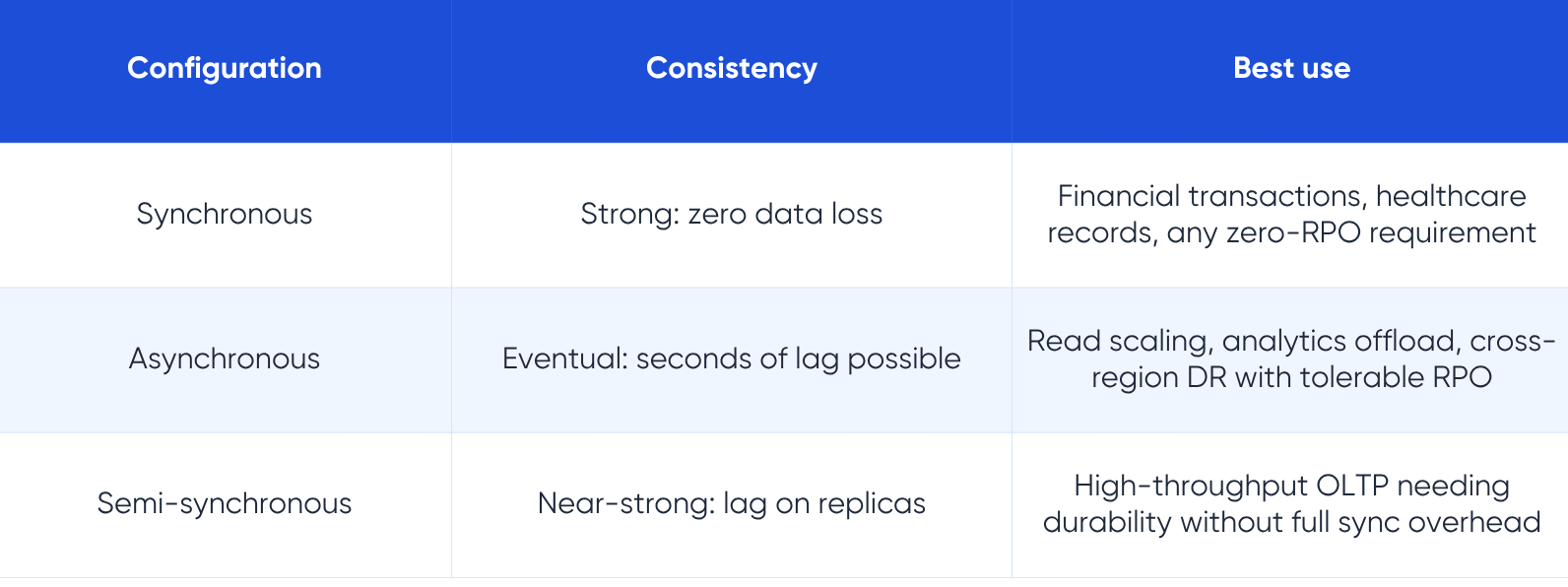
Once captured, changes must be transmitted to the target. In synchronous replication, the primary database does not acknowledge a write to the application until the target has confirmed receipt and committed the same change. In asynchronous replication, the primary confirms immediately and sends the change to the target in the background. Semi-synchronous sits between the two: the primary waits for at least one target to acknowledge receipt of the log record before confirming, without waiting for the full commit to complete.
The transmission path, its bandwidth, its latency, and its reliability, is often where replication problems surface first. Cross-region replication adds 50 to 300 milliseconds of network round-trip time that synchronous configurations must absorb on every write.
Stage 3: Application
The target database receives the replication stream and applies each change in the same order it occurred on the source. For physical replication, this means applying raw log blocks. For logical replication, which most CDC-based tools use, it means decoding the log into row-level events and applying them through the standard database write path.
In modern CDC pipelines, the sub-second target for replication lag from commit on the source to delivery at the target is achievable in most same-region configurations. Research from Streamkap benchmarks typical CDC delivery at 200 to 500 milliseconds from source commit to target receipt.
Stage 4: Consistency verification
A production replication setup includes continuous monitoring of replication lag, which is the time difference between the latest committed transaction on the primary and the most recent transaction applied on the replica. Lag that grows without bound is a system in distress. Monitoring replication lag, and alerting when it exceeds defined thresholds, is a non-negotiable operational requirement.
A replication setup with no lag monitoring is not a replication strategy. It is an untested assumption.
Database replication types: the taxonomy that matters
Replication is not a single technique. It is a family of approaches with different consistency guarantees, latency characteristics, and operational complexity. The following taxonomy maps the primary types to the decisions they influence.
Primary-replica replication (formerly master-slave)
This is the canonical replication topology and the most widely deployed in production. One node, called the primary, leader, or historically the master, accepts all write operations. One or more replica nodes, formerly called slaves and now commonly called replicas, followers, or secondaries, receive a continuous stream of changes from the primary and serve read queries.
The primary enforces write ordering. Because all writes flow through a single point, conflicts are structurally impossible. Replicas can serve reads, reducing load on the primary during analytics, reporting, and BI workloads. In a failure scenario, a replica can be promoted to primary, though the promotion process and its implications for replication lag must be planned carefully.
Terminology note: The industry has largely moved away from master/slave terminology. MySQL 8.0, PostgreSQL, and most modern tooling now use primary/replica or leader/follower. The underlying architecture is identical.
Multi-primary replication (formerly master-master)
Multiple nodes each accept write operations. Changes are bidirectionally synchronized between primaries with conflict resolution logic applied when the same row is modified concurrently on two nodes. This architecture enables write throughput to scale across multiple nodes and allows any node to serve both reads and writes, simplifying application routing.
The engineering cost is substantially higher. Conflict resolution is a genuinely hard problem: when two primaries update the same row at the same millisecond, one of those updates must be discarded or merged. Strategies include last-write-wins based on timestamp, application-defined rules, or manual resolution queues. None of these is free.
Architecture warning: Multi-primary replication is frequently over-engineered into situations that do not require it. Before committing to multi-primary, verify that your write workload genuinely exceeds what a single primary with read replicas can handle. In most enterprise environments, a well-tuned primary-replica setup with proper read routing covers the vast majority of workloads.
Cascaded replication
A replica itself becomes the source for further downstream replicas. This fan-out pattern reduces load on the primary while distributing data to multiple consumers. A common pattern positions one replica as the source for downstream analytics feeds, search platform synchronization, and compliance archives, so that none of these consumers place any load on the primary database.
Log-based and CDC replication
Rather than polling tables, log-based CDC reads the database transaction log directly and converts each committed change into a structured event. The event stream can feed a single target database or be routed to multiple consumers simultaneously: a Kafka topic, a data warehouse, a search index, a cache invalidation service. This is the standard for real-time data pipelines in modern data architectures.
CDC delivers changes with near-zero impact on the source database because it reads the log, not the tables. There are no SELECT queries contending with production traffic. Most production CDC pipelines achieve sub-second lag within the same region.
Database backup vs replication: different tools for different failures
This comparison generates more confusion than any other in database architecture. Both backup and replication produce copies of data, and both contribute to a recovery strategy. The differences are in what they protect against and how quickly they restore service.
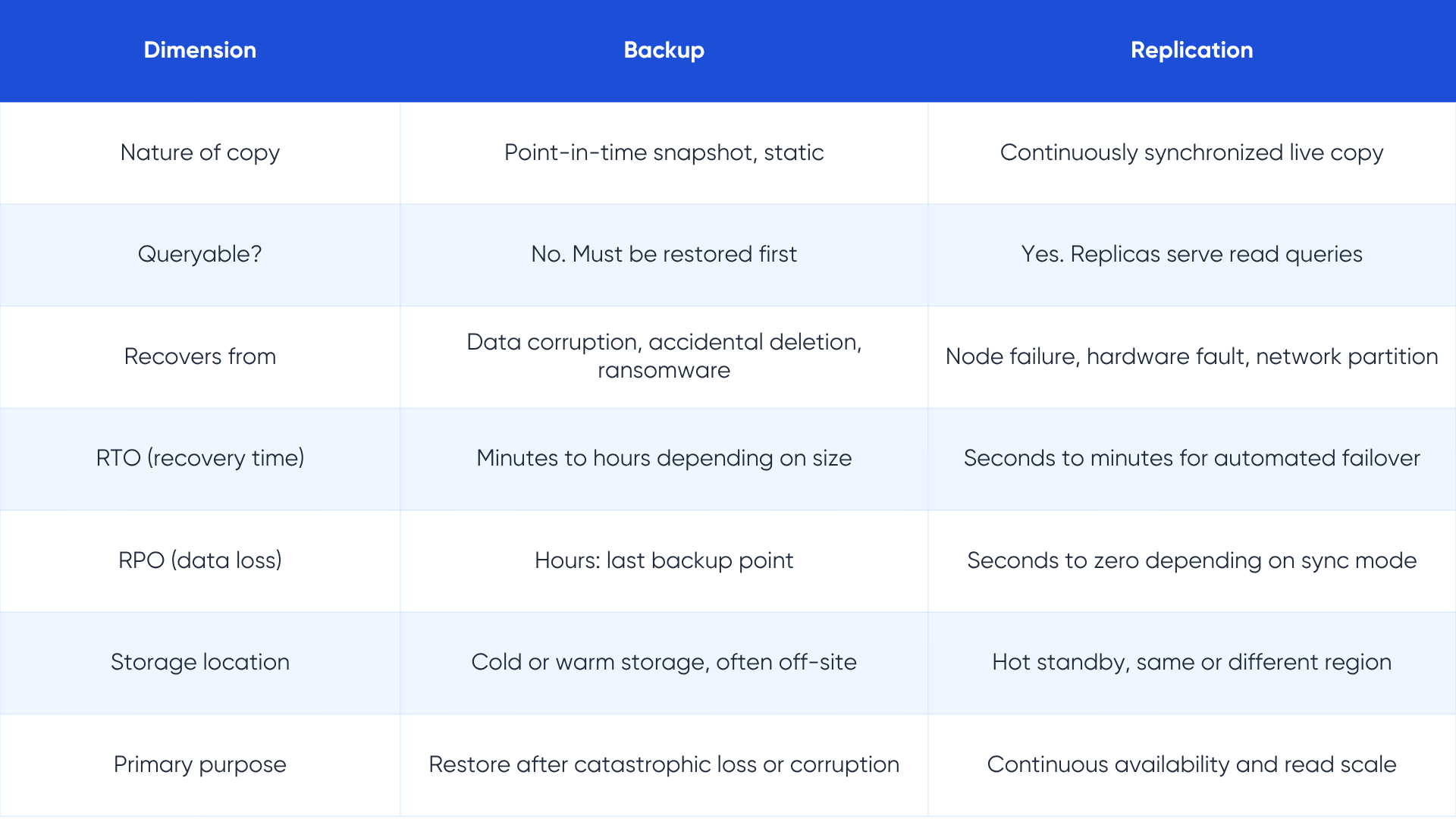
The critical insight is this: replication does not protect against logical corruption. If a developer accidentally runs a DELETE without a WHERE clause on the primary, that deletion is faithfully replicated to every replica within milliseconds. Your replication setup will have perfectly synchronized the disaster to all targets. You need a backup to recover from that scenario.
Conversely, backup alone cannot provide continuous availability. If the primary database fails at 2:00 AM, restoring from a backup taken at midnight means losing two hours of transactions, and the restore itself may take an hour or more for large databases. Replication, with automated failover, gets you back online in under two minutes with little or no data loss.
The mature approach
Production data strategy combines both: replication for uptime and read scale, backups for recovery from logical errors and ransomware. The two are complementary, not competitive. Organizations that treat them as alternatives are leaving one category of risk entirely uncovered.
Database clustering vs replication: availability vs scale
Database clustering and replication are often used in the same sentence, and sometimes together in the same architecture. They are not the same thing, and conflating them leads to architectures that are either over-engineered or do not actually achieve their availability goals.
What clustering is
A database cluster is a group of two or more server instances that work together as a single logical database system. All nodes in the cluster share either the same storage (shared-disk clustering) or maintain synchronized copies of data across nodes (shared-nothing clustering). Applications see one database endpoint, not multiple. Clustering provides high availability through redundancy at the node level: when one node fails, another takes over without application changes.
What replication is, in this context
Replication creates independent copies of a database, typically with a clear hierarchy (primary and replicas), each running on separate storage. Replicas can be queried for reads, reducing load on the primary. They can be located in different regions. They do not share storage with the primary.
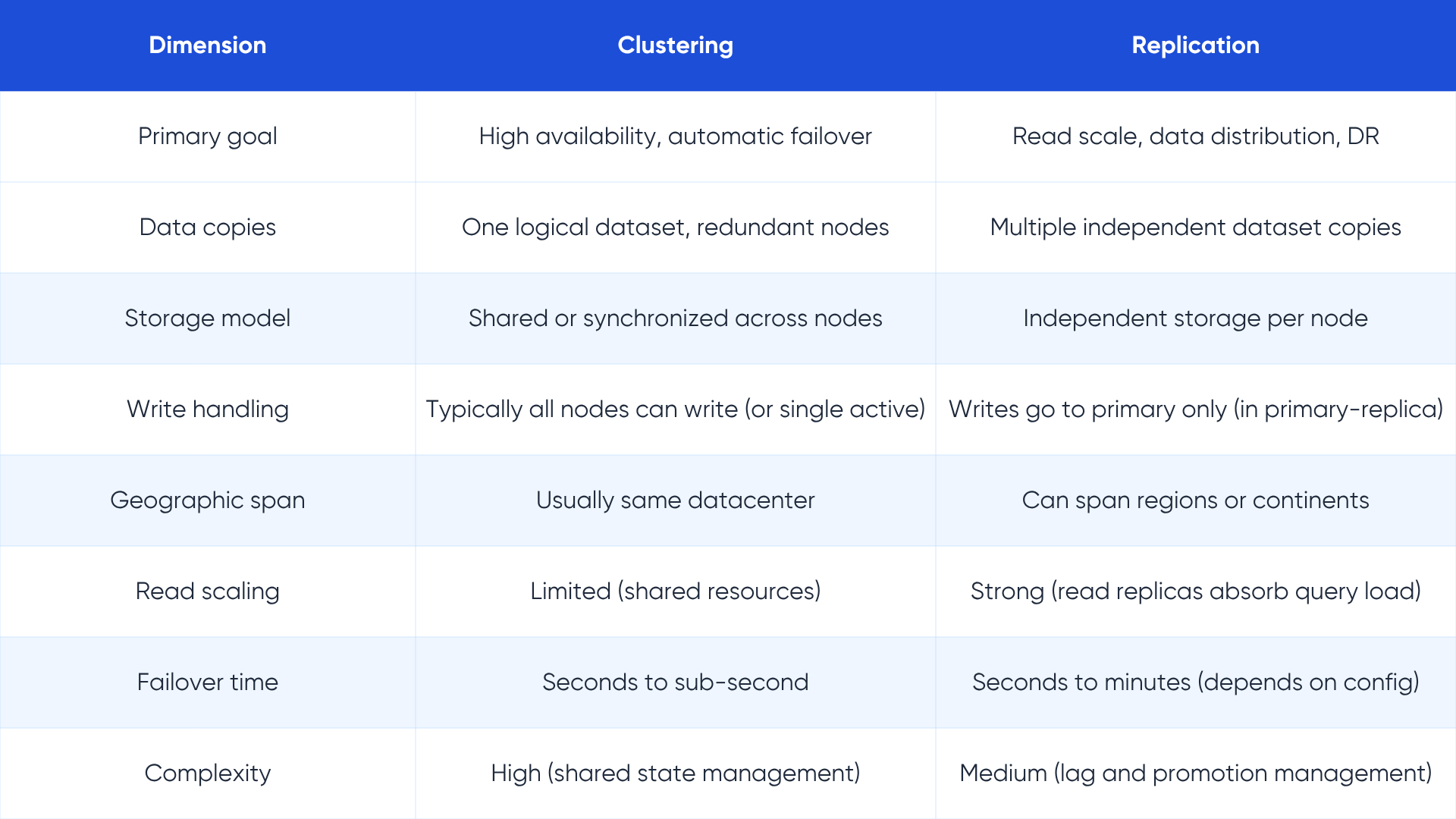
In practice, many enterprises use both together. A MySQL cluster or PostgreSQL cluster provides high availability within a datacenter, while asynchronous read replicas distribute query load and cross-region replicas provide geographic redundancy. The cluster handles millisecond-level failover; the replicas handle the read workload and longer-distance DR.
Database mirroring vs replication: scope and purpose
Database mirroring duplicates an entire database, including its schema, stored procedures, security credentials, triggers, indexes, and all objects, to a mirror server. The mirror is a complete twin of the original, not just a copy of the data. Mirroring works at the level of physical transaction log records, not at the logical level of individual rows or tables.
Replication, by contrast, operates at the logical level of data and database objects. It typically replicates a defined subset of tables, views, or stored procedures, not the complete database environment. This makes replication more flexible for heterogeneous targets, where the source is Oracle and the target is PostgreSQL for example, but means the target is not a complete drop-in replacement for the source.
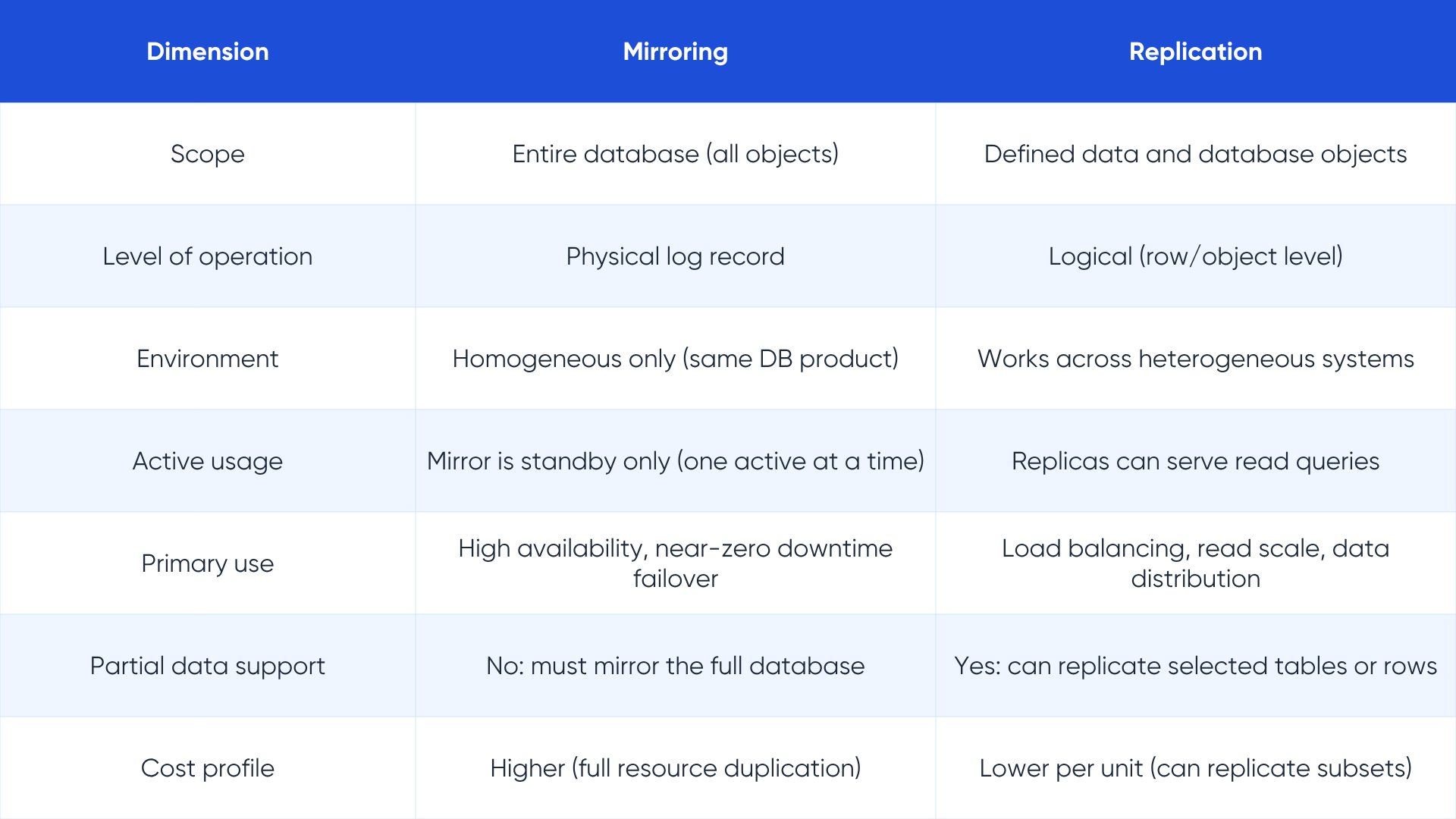
Microsoft deprecated SQL Server's native database mirroring in SQL Server 2012, replacing it with Always On Availability Groups, which provide more flexibility by combining some characteristics of both mirroring and replication. Understanding the mirroring concept remains valuable for evaluating legacy architectures and for understanding the design tradeoffs in any high-availability setup.
For teams modernizing SQL Server architectures
If you are evaluating or modernizing a SQL Server environment that uses database mirroring, LakeStack's data infrastructure services page covers current patterns for high availability and disaster recovery in enterprise database environments.
Database master-slave replication: the foundational pattern
Despite the terminology shift toward primary-replica, the architectural pattern remains the most widely deployed replication topology in the world. MySQL, PostgreSQL, MongoDB, Redis, and virtually every major database engine supports it natively. The concept is simple enough to explain in one sentence: one node handles all writes and sends those writes to one or more nodes that handle reads.
How the primary processes writes
When an application sends a write to the primary, the primary records the change in its transaction log before applying it to the data files. This sequence is the foundation of the replication guarantee. For MySQL, the change lands in the binlog first. For PostgreSQL, it goes to the WAL. For Oracle, it enters the redo log. The log entry becomes the authoritative record that replicas consume.
How replicas consume changes
Each replica maintains a connection to the primary and continuously reads the replication stream. The replica applies each change in the exact order it was committed on the primary, maintaining transactional consistency. Because the replication log preserves ordering, replicas are guaranteed to arrive at the same state as the primary given enough time.
In asynchronous mode, which is the most common production configuration, the replica may be a fraction of a second to several seconds behind the primary. This lag is the trade-off for performance. In synchronous mode, the primary waits for at least one replica to confirm receipt before acknowledging the write, guaranteeing zero lag at the cost of higher write latency.
Handling replica failures and lag
When a replica falls behind due to network issues or hardware saturation, it catches up by reading from the primary's log at a higher rate. Modern database engines support parallel replication to accelerate this catch-up. If a replica has been offline long enough that the primary has rotated past the log segment the replica needs, the replica must resync from a fresh snapshot, which for large databases can take hours.
Promoting a replica to primary
When the primary fails, one replica is promoted to become the new primary. The promotion process is where most replication architectures get complicated. The promoted replica may not have received all changes the primary committed immediately before failing, depending on the replication mode. This potential data loss window is the RPO of your replication setup. In synchronous mode, RPO is zero. In asynchronous mode, RPO is the replication lag at the moment of failure.
Automated failover tools like Patroni for PostgreSQL, MySQL Orchestrator, and cloud-managed services like AWS RDS Multi-AZ handle promotion automatically within 60 to 120 seconds in most configurations. Manual failover without these tools can take much longer and introduces human error risk.
Database replication vs sharding: scale versus availability
Sharding and replication are the two most commonly confused concepts in database scaling discussions, partly because both involve distributing data across multiple systems. They solve fundamentally different problems, and confusing them leads to architectures that are unnecessarily complex or that fail under exactly the load they were designed to handle.
Replication copies the same data to multiple nodes. Sharding distributes different data to different nodes. These are opposite operations.
What sharding does
Sharding splits a large database horizontally, partitioning rows into independent subsets called shards, each stored on a separate server. A user table with one billion rows might be split into ten shards, each holding 100 million rows, with shard assignment determined by a shard key such as user ID, region, or hash.
Every shard operates as its own database. Sharding enables write throughput to scale beyond the capacity of any single server, because writes are distributed across all shards. A single server handling 100,000 writes per second becomes ten servers each handling 10,000 writes per second.
The engineering cost of sharding
Sharding adds significant complexity. Applications must know how to route queries to the correct shard. Cross-shard queries that join data from multiple shards require coordination overhead that can be slower than the equivalent query on a single unsharded database. Schema changes must be applied to every shard simultaneously. Rebalancing shards as data grows is operationally intensive.
Sharding is the right answer when your data volume or write throughput has genuinely exceeded what a single well-tuned primary can handle. It is not the right answer for read-heavy systems, where replication solves the problem at a fraction of the complexity.
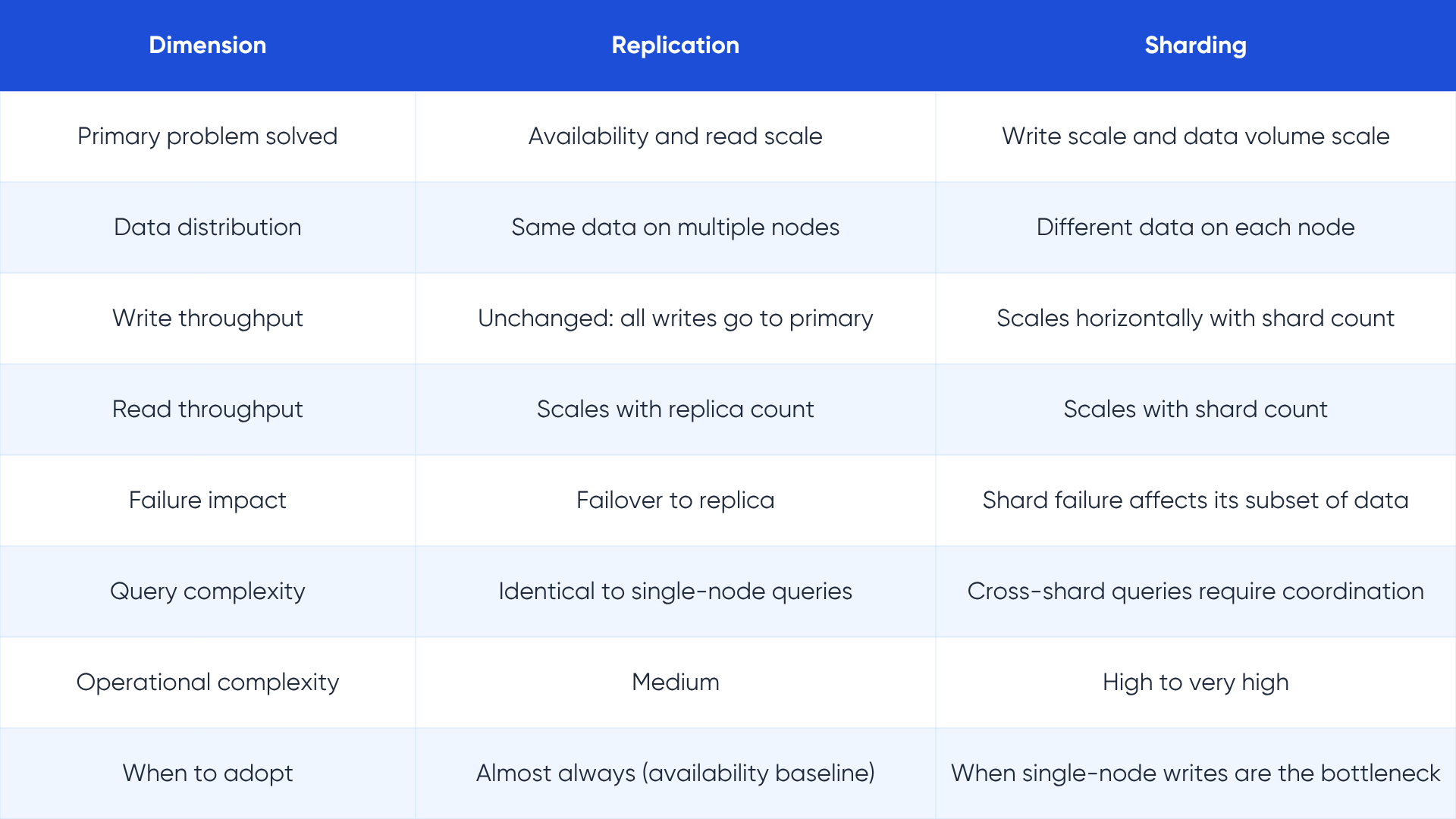
Database sharding vs partitioning vs replication: completing the picture
Partitioning is the concept that confuses the sharding comparison further. Partitioning, sharding, and replication are three distinct techniques, and they form a hierarchy of scale decisions that architecture teams work through in sequence.
Partitioning: organization within a single database
Partitioning divides a large table into smaller, logically separate pieces, called partitions, within the same database instance. A two-billion-row orders table might be partitioned by month, so that querying orders from the last quarter scans only the relevant partitions rather than the entire table. Partitioning improves query performance and simplifies maintenance such as archiving old data, but it does not move data to different servers.
Sharding: partitioning across servers
Sharding takes the partitioning concept and extends it across multiple servers. Each shard is effectively a separate database instance holding its own partition of the data. Sharding is horizontal partitioning at the infrastructure level rather than within a single database server. The distinction that matters for architecture: partitioning is an internal database optimization, while sharding is a distributed systems design decision with implications for application code, query routing, and operational processes.
Combining all three
Large-scale systems typically use all three together. Partitioning optimizes query performance within each shard. Sharding distributes write load across multiple servers. Replication provides fault tolerance and read scale for each shard. MongoDB's architecture is the canonical example: a sharded cluster where each shard is itself a replica set, providing both horizontal write scale via sharding and fault tolerance via replication within each shard.

Database replication architecture: the patterns that define production systems
Understanding the vocabulary of replication types is necessary but not sufficient. Production replication architectures combine these patterns in specific topologies that reflect the business requirements for availability, performance, and geography. Here are the four most common production topologies.
Active-passive: the standard baseline
One primary active node handles all reads and writes. One or more passive replicas receive the replication stream but serve no production traffic, existing solely for failover. When the primary fails, a passive replica is promoted and begins serving traffic. This is the simplest architecture and the right starting point for most organizations that are not yet at the scale where read replicas are needed.
Active-active reads: primary with read replicas
One primary handles all writes. One or more read replicas handle read queries, reducing load on the primary. Applications must route writes to the primary and reads to the replica pool. This is the standard architecture for read-heavy workloads: e-commerce product catalogs, analytics dashboards, reporting systems, and content platforms. AWS RDS supports up to 15 read replicas per primary. Aurora MySQL supports up to 15 Aurora Replicas, with lag typically under 10 milliseconds.
Multi-region active-passive
A primary in one region replicates asynchronously to a replica in one or more other regions. The cross-region replica serves local read traffic for users in that geography and acts as the DR target if the primary region becomes unavailable. This architecture accepts replication lag for the geographic efficiency and disaster resilience it provides.
Active-active writes: multi-primary
Multiple nodes accept writes simultaneously. This topology requires conflict resolution logic and is significantly more complex than the others. It is appropriate for globally distributed applications where write latency to a single primary region is unacceptable for users in distant locations, and where the application can tolerate or resolve occasional write conflicts. CockroachDB, Cassandra, and MySQL Group Replication are the most common implementations.
For teams designing global data architectures
Replication topology decisions interact closely with your data pipeline design and analytics architecture. LakeStack's data architecture services help organizations navigate these topology choices in the context of their full data stack. Our previous reference on database replication strategies covers the underlying methods that these topologies build on.
The decision framework: which approach for which problem
The confusion between backup, replication, clustering, mirroring, sharding, and partitioning exists because every real system needs more than one of them. The question is not which one to choose, but which combination to compose for your specific requirements.
Start with your failure scenarios
List the specific failure modes your system must survive: hardware failure, software bugs, accidental data deletion, natural disasters, ransomware, and regional cloud outages. Each failure mode maps to a different protection mechanism. Hardware failure at the node level points to clustering or replication with automatic failover. Accidental deletion points to backup. Regional cloud outage points to cross-region replication. Ransomware points to immutable backups with offline or air-gapped copies.
Define RPO and RTO before touching configuration
Recovery Point Objective is the maximum data loss your business can accept expressed in time. Recovery Time Objective is the maximum downtime. For a payment processor, RPO is zero and RTO may be under 30 seconds. For an internal analytics dashboard, RPO of two hours and RTO of four hours may be entirely acceptable. These numbers determine whether you need synchronous replication, asynchronous replication, clustering, or backup alone.
Map the workload before adding complexity
Before adding read replicas, measure whether your read workload actually saturates the primary. Before considering sharding, verify that the write throughput has exceeded single-node capacity with tuning applied. Before implementing multi-primary, confirm that write latency to a single primary is genuinely causing user-facing problems. Most systems perform better with a simpler architecture that is operated excellently than with a complex one that is operated adequately.
The minimum viable data protection stack
For most enterprises operating on cloud infrastructure, the following combination covers the most critical failure scenarios without unnecessary complexity:
- Synchronous replication within the same region via a managed HA service (AWS RDS Multi-AZ, Google Cloud SQL HA, Azure Database for PostgreSQL Flexible Server)
- Asynchronous cross-region replication or read replicas for DR and geographic read performance
- Daily point-in-time backups with 30-day retention, stored in a different account or region from the primary
- Regular failover testing: at minimum quarterly, under production-realistic load
Industrial realities in 2026
The theory of replication and the practice of operating it at scale have some important gaps. Here is what production experience teaches.
Replication lag spikes are almost always underestimated
Organizations design for average replication lag and get surprised by peak lag. During high-write bursts, such as end-of-month batch processes, Black Friday traffic, or major data imports, lag on asynchronous replicas can spike from milliseconds to minutes. Applications that read from replicas without accounting for this can make business-critical decisions on stale data. Monitoring average lag is necessary but not sufficient. Monitor maximum lag over time and design for it.
The split-brain risk is real and underappreciated
Split-brain is the condition where two nodes simultaneously believe they are the primary, both accepting writes, with no coordination between them. When the network between a primary and its replica is interrupted but both nodes remain operational, automated failover can promote the replica while the original primary continues serving traffic. The result is two primaries diverging independently. Protecting against split-brain requires quorum-based consensus or a witness node that can arbitrate promotion decisions. Cloud-managed services handle this automatically; self-managed replication requires deliberate configuration.
Sharding is almost always adopted later than it should be
Organizations typically introduce sharding reactively, when a single-node database is already under performance pressure. Retrofitting sharding into an application that was not designed for it requires significant application refactoring: query routing logic, shard-aware ORM configuration, and resharding procedures for existing data. Teams that anticipate sharding early and design their application with shard keys in mind avoid this pain even if they do not implement sharding immediately.
The enterprise data integration market context
The enterprise data integration market, which includes replication tooling, is projected to grow from $15.22 billion in 2026 to over $30.17 billion by 2033. This growth is driven by the increasing complexity of multi-cloud environments, the demand for real-time analytics, and the growing regulatory requirements for data sovereignty and availability. The tooling landscape is maturing rapidly, with managed services increasingly removing the operational burden that once required dedicated database administrators to maintain replication configurations.
Quick reference: matching the technique to the problem
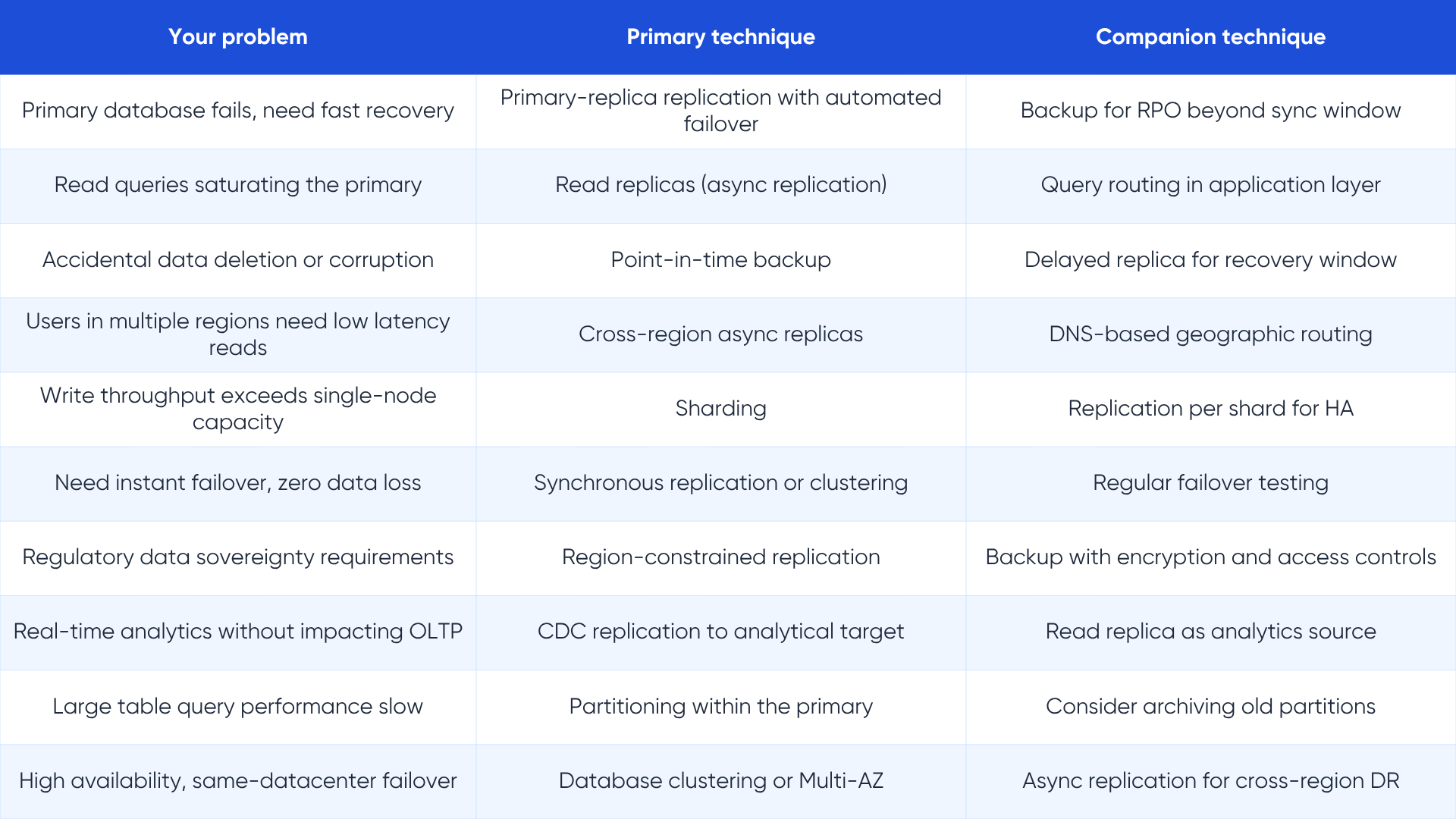
Key takeaways
- Backup and replication protect against different failures. Backup recovers from logical corruption and deletion. Replication recovers from node and hardware failures. Mature systems use both.
- Clustering provides high availability within a datacenter. Replication provides read scale and cross-region resilience. Most enterprise architectures use both together.
- Mirroring duplicates an entire database environment including all objects. Replication copies defined data and objects and works across heterogeneous systems.
- Primary-replica (formerly master-slave) replication is the foundational pattern. Every write goes to the primary. Replicas handle reads. One node is the source of truth.
- Replication copies the same data to multiple nodes. Sharding distributes different data to different nodes. They are complementary, not interchangeable.
- Partitioning is an optimization within a single database. Sharding extends that concept across multiple servers. Production systems often use all three: partitioning, sharding, and replication.
- Define RPO and RTO before selecting any technology. The recovery objectives determine the architecture. The architecture determines the tools.
- Replication lag under peak load is almost always higher than under average load. Design and monitor for peak, not average.
Sources and citations
[1] N-able. The True Cost of Downtime: Why Cyber Resilience Matters. n-able.com/blog/true-cost-of-downtime. November 2025. Citing ITIC 2024 survey.
[2] Data Horizzon Research. Data Replication Market Size, Growth, Share and Analysis Report 2033. datahorizzonresearch.com. 2023.
[3] Integrate.io. Database Replication Speed Metrics: 40 Statistics Every IT Leader Should Know in 2026. integrate.io/blog/database-replication-speed-metrics/
[4] Streamkap. Database Replication Patterns: Active-Active, CDC, and Beyond. streamkap.com/resources-and-guides/database-replication-patterns. March 2026.
[5] Skyvia. Database Replication: The Ultimate Guide for 2026. skyvia.com/blog/database-replication/. January 2026.
[6] Microsoft Learn. Database Mirroring (SQL Server). learn.microsoft.com/sql/database-engine/database-mirroring/database-mirroring-sql-server. September 2025.
[7] Stelo Data. What is the Difference Between Data Replication and Database Mirroring? stelodata.com/blog/data-replication/mirroring-vs-replication. September 2022.
[8] GeeksforGeeks. Difference Between Database Sharding and Replication. geeksforgeeks.org. September 2025.
[9] SingleStore. Database Partitioning vs Sharding: What is the Difference? singlestore.com/blog/database-sharding-vs-partitioning. January 2026.
[10] iam.slys.dev. Sharding vs Partitioning vs Replication: Embrace the Key Differences. July 2025.
[11] Streamkap. Getting Started with CDC: Your First Real-Time Data Pipeline. streamkap.com/resources-and-guides/cdc-getting-started. February 2026.
[12] Stacksync. 9 Data Replication Tools You Need in 2026. stacksync.com/blog. March 2026. Citing enterprise data integration market forecast.
[13] Medium / CodeBook. Master-Slave Architecture (Leader-Based Replication). codexbook.medium.com. November 2023.
[14] Navidbarsalari on Medium. Master-Slave Database Architecture: A Complete, High-Level, Technical Guide. November 2025.
[15] GeeksforGeeks. Difference Between Database Sharding and Partitioning. geeksforgeeks.org. January 2026.
[16] Ivan Fedianin. Understanding Leader-Follower Replication. fedianin.com. March 2025.
About LakeStack
LakeStack helps enterprise data teams design, build, and operate data infrastructure that performs reliably at scale. From database architecture to real-time data pipelines and lakehouse design, our engineering teams work alongside yours to solve the problems that matter. For a deeper look at the specific replication methods referenced throughout this guide, see our companion reference: Database replication strategies: the definitive guide for enterprise data leaders, available in the LakeStack blog.



