

.png)
What's in this guide
01 Why change data capture has become a critical infrastructure decision
02 What is change data capture and how does it work?
03 The CDC data flow: from source to destination
04 The three methods of change data capture
05 CDC vs ETL: understanding the difference
06 Change data capture use cases: where it delivers the most value
07 Log-based CDC: the technical standard and why it matters
08 Change data capture best practices for IT leaders
09 Common CDC challenges and how to solve them
10 How to evaluate and implement a CDC solution
11 Frequently asked questions
Why change data capture has become a critical infrastructure decision
A major e-commerce platform discovered in 2023 that its inventory data was consistently 47 minutes behind its operational database. Every time a product sold out, the data warehouse, which powered its pricing engine and recommendation system, had no idea for nearly an hour. The result: customers were shown recommendations for out-of-stock products, promotions were triggered for items that no longer existed, and the pricing engine made decisions based on stale inventory signals. The root cause was a nightly batch ETL job that had been in place since 2019.
Change data capture is the technology that eliminates this problem. Rather than copying entire tables on a schedule, CDC continuously monitors the operational database for changes, every insert, update, and delete, and propagates those changes to downstream systems within milliseconds. It is the difference between a data platform that reflects your business as it is now, versus one that reflects your business as it was hours ago.
In 2026, three forces have made CDC a strategic infrastructure priority rather than a niche engineering concern:
- Real-time AI requirements: AI models making real-time decisions, fraud detection, dynamic pricing, personalisation, require data that is current to the second, not the hour. CDC is the standard mechanism for feeding operational data into AI inference pipelines with sub-second latency.
- Microservices and distributed systems: As organisations decompose monolithic applications into microservices, the need to keep multiple databases in sync without tight coupling has made CDC a core architectural pattern for event-driven systems.
- Regulatory data freshness requirements: Financial services, healthcare, and other regulated industries increasingly face requirements for near-real-time data accuracy in reporting systems. Batch ETL cycles that were acceptable in 2018 are compliance risks in 2026.
What is change data capture and how does it work?
Change data capture is a software design pattern and set of technologies that monitor a source database for data changes and deliver those changes, in near real time, to one or more downstream consumers. The term 'capture' is deliberate: CDC does not pull entire datasets. It captures only the delta, the specific rows that changed, the nature of the change (insert, update, or delete), and the metadata about when and how the change occurred.
The core mechanism differs by method, but the fundamental premise is consistent: instead of asking 'what does the entire table look like now?' on a schedule, CDC asks 'what changed since the last event?' continuously. This shift from polling to event-driven data movement is what makes CDC fundamentally different from, and in many cases superior to, traditional batch ETL.
What CDC captures
A well-implemented CDC system captures three types of data change events:
- INSERT events: A new row has been added to the source table. CDC captures the full content of the new row along with the timestamp and transaction ID.
- UPDATE events: An existing row has been modified. CDC captures both the before image (the original values) and the after image (the new values), enabling downstream systems to understand exactly what changed.
- DELETE events: A row has been removed from the source table. CDC captures the primary key and metadata of the deleted row, enabling downstream systems to propagate the deletion rather than simply stop seeing the record.
CDC does not move data. It moves change events. This distinction is why CDC can keep petabyte-scale data systems synchronised with millisecond latency, it only ever moves what actually changed, not what stayed the same.
The CDC data flow: from source to destination
The following diagram shows how change data capture works in practice, from the moment a change occurs in an operational database to the moment it is available in downstream systems.
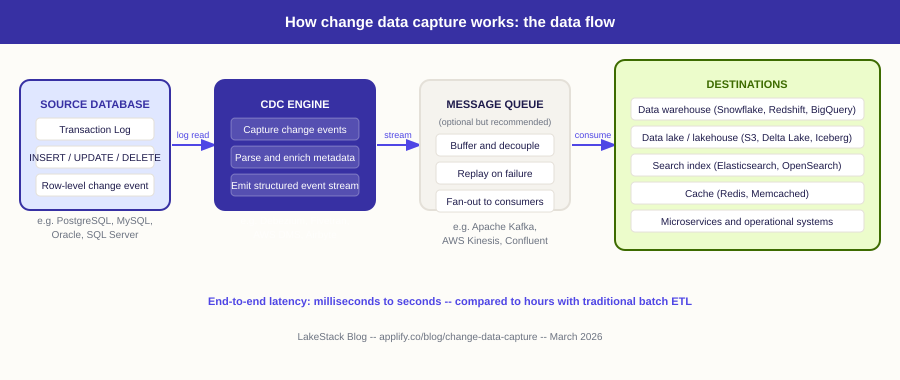
The key architectural insight is that CDC decouples the source database from its consumers. The source database writes to its transaction log as it normally would. The CDC engine reads that log independently, without adding query load to the production database. Downstream consumers receive a stream of precisely what changed, when it changed, and what the data looked like before and after.
Why the message queue matters
The message queue layer (Kafka, Kinesis) between the CDC engine and its consumers is architecturally important, not optional. It provides replay capability if a consumer fails, fan-out to multiple downstream systems from a single CDC stream, and back-pressure management so a slow consumer cannot block the CDC pipeline. Without it, a single slow or failed consumer can disrupt the entire integration.
The three methods of change data capture
Not all CDC implementations are equal. The three primary methods differ significantly in their performance impact on source systems, their reliability, and the richness of the change information they can capture. Understanding these differences is essential for IT decision makers evaluating CDC solutions.
Method 1, Industry standard
Log-based CDC
Log-based CDC reads the database transaction log, the write-ahead log (WAL) in PostgreSQL, the binary log (binlog) in MySQL, or the redo log in Oracle, to capture change events. Because the transaction log is written by the database engine as part of its normal operation, log-based CDC introduces virtually zero additional load on the production database. It is the most reliable, lowest-impact, and highest-fidelity method available.
Pros: zero production load, captures all change types (INSERT, UPDATE, DELETE), preserves exact before/after values, sub-second latency. Cons: requires database-level permissions to access the log, and not all databases expose their transaction logs equally.
Method 2, Simple but limited
Timestamp-based (query-based) CDC
Timestamp-based CDC queries the source database on a schedule, comparing a 'last_modified' or 'updated_at' timestamp column to identify rows changed since the last query. It is the simplest method to implement and requires no special database permissions, but it has significant limitations. It cannot detect hard deletes (rows that have been removed leave no timestamp trace), it adds query load to the production database, and it is only as fresh as its polling interval.
Pros: simple to implement, works on any database with a timestamp column, no special permissions required. Cons: cannot capture hard deletes, adds query load, minimum latency limited by polling interval, misses rapid changes between polls.
Method 3, Niche use cases only
Trigger-based CDC
Trigger-based CDC uses database triggers, procedures that fire automatically on INSERT, UPDATE, or DELETE operations, to write change records to a separate audit or shadow table. A separate process then reads and forwards these records. While trigger-based CDC can capture all change types, the triggers themselves add write overhead to every source database operation, making this method unsuitable for high-volume transactional systems. It is appropriate only for low-write-volume databases where other methods are not available.
Pros: captures all change types, works on databases without log access. Cons: adds write overhead to every source database operation, difficult to maintain, can cause deadlocks at high volume, not recommended for production transactional systems.
The recommendation for IT decision makers
For the vast majority of production use cases, log-based CDC is the correct choice. It is the only method that captures all change types with zero production database impact and sub-second latency. If your evaluation of a CDC vendor or tool does not start with log-based CDC support for your specific database, the evaluation is starting from the wrong place.
CDC vs ETL: understanding the difference
CDC and ETL are frequently confused because they both move data between systems. The distinction is fundamental, and choosing the wrong approach for a given use case creates either unnecessary complexity or inadequate performance.
.png)
ETL asks: what does the data look like now? CDC asks: what just changed? These are fundamentally different questions, and the right tool depends entirely on which question your downstream system needs answered.
In practice, most mature data architectures use both. ETL or ELT handles the initial historical load of data into analytical systems. CDC then keeps that data current by propagating changes in real time. The two patterns are complementary, not competitive.
Change data capture use cases: where it delivers the most value
CDC is not the right tool for every data movement requirement. It delivers disproportionate value in specific contexts where data freshness, source database impact, or change fidelity are critical constraints.
Real-time analytics and operational dashboards
Business operations teams, trading desks, and operations centres increasingly require dashboards that reflect what is happening right now, not what happened two hours ago. CDC feeds data warehouses and BI tools with a continuous stream of changes, enabling dashboards that update within seconds of an operational event. The alternative, frequent ETL runs, adds significant query load to production databases and still delivers data that is minutes old.
Database replication and disaster recovery
CDC is the foundation of database replication, keeping a standby or read replica synchronised with a primary database. In disaster recovery architectures, CDC reduces the recovery point objective (RPO) to near zero by continuously streaming changes from the primary to the standby. Traditional backup-based recovery accepts hours of data loss; CDC-based replication accepts seconds.
Source: AWS, Azure, and Google Cloud all use CDC (specifically log-based replication) as the mechanism for their managed database read replica services
Data migration with zero downtime
Migrating a production database to a new platform, from on-premise to cloud, or from one database engine to another, traditionally requires a maintenance window during which the old system is frozen and the new system catches up. CDC eliminates this constraint. The new system is populated with a full historical load, and CDC then streams all subsequent changes. When the new system is fully caught up, cutover happens with seconds of downtime rather than hours.
Event-driven microservices and the outbox pattern
In microservices architectures, services must communicate state changes to each other without tight coupling. The outbox pattern uses CDC to turn database writes into reliable event streams: a service writes to its local database (which it can do atomically), and CDC captures that write and publishes it to a message queue for other services to consume. This pattern guarantees that every database write is also published as an event, no lost messages, no dual-write consistency problems.
Search index and cache synchronisation
Keeping a search index (Elasticsearch, OpenSearch) or cache (Redis, Memcached) in sync with an operational database is a classic CDC use case. Rather than rebuilding the search index on a schedule, CDC streams every database change directly into the index in near real time. Users see search results that reflect changes made seconds ago, not hours ago.
Real-time fraud detection and risk monitoring
Financial fraud detection systems require transaction data the moment it is written. A batch ETL process that runs every 30 minutes gives fraudsters a 30-minute window to complete multiple fraudulent transactions before detection. CDC streams every transaction to the fraud detection model within milliseconds, enabling rules and ML models to act before the next transaction occurs.
Log-based CDC: the technical standard and why it matters for IT leaders
Log-based CDC has become the dominant standard for production CDC implementations, and understanding why, at a level sufficient for an IT decision maker, is important for evaluating vendor claims and architectural proposals.
What a transaction log is
Every production relational database maintains a transaction log, variously called the write-ahead log (WAL) in PostgreSQL, the binary log (binlog) in MySQL, the redo log in Oracle, or the transaction log in SQL Server. This log records every change made to the database before it is committed, ensuring that the database can recover from crashes and that replicas can be kept synchronised with the primary. The log is an ordered, append-only sequence of change records that the database engine writes as part of its normal operation.
How CDC reads the log
Log-based CDC tools connect to the database as if they were a replica, they request the log stream starting from a specific position and receive a continuous feed of change events. Because they are reading from the log, not querying the data tables, they add virtually zero load to the production database. The database does not know or care that the CDC tool is reading its log; it writes the log the same way regardless.
Why database-level configuration matters
Log-based CDC requires the source database to be configured to retain the log for long enough for the CDC tool to read it, and in a format that exposes the information needed. For PostgreSQL, this means enabling logical replication (wal_level = logical). For MySQL, this means enabling the binary log in row-based format. For SQL Server, this means enabling Change Data Capture at the database level. These are non-default configurations in most database installations, they must be explicitly enabled, and they slightly increase storage requirements for log retention.
Enabling log-based CDC on a production database is a database administration decision, not just a data engineering decision. It requires DBA sign-off on the replication user permissions, log retention policy, and the potential impact on database storage. Any CDC implementation that skips this conversation is building on an unsecured foundation.
Schema evolution and why it requires active management
When the schema of a source table changes, a column is added, renamed, or its data type is changed, the CDC stream must handle that change gracefully. Without active schema management, a column rename can cause the CDC pipeline to fail silently or deliver incorrect data to downstream consumers. Production-grade CDC tools provide schema registry integration (Kafka's Schema Registry, for example) and schema evolution policies that define whether schema changes are backward-compatible, and what happens when they are not.
Change data capture best practices for IT leaders
Start with the initial full load
CDC captures changes from a point in time. Before CDC can keep a downstream system current, that system needs to contain all the historical data that existed before CDC began. The standard pattern is: perform a full initial load of all existing data, mark the log position at which the load completed, and then start the CDC stream from that position. Never start CDC without completing the initial load first, the result is a downstream system that is missing all historical records.
Design for failure and recovery from day one
CDC pipelines will encounter network interruptions, source database restarts, and consumer failures. A production-grade CDC implementation handles these gracefully: the CDC engine tracks its position in the transaction log (the offset or LSN) persistently, so it can resume from exactly where it stopped. Downstream consumers must be idempotent, capable of handling the same event more than once without producing incorrect results, because at-least-once delivery is the standard guarantee in CDC systems.
Monitor pipeline lag, not just pipeline health
A CDC pipeline that is running without errors but is 30 minutes behind the source database is not healthy, it is broken for real-time use cases. Monitor replication lag (the time between a change occurring in the source and arriving at the destination) as a primary SLA metric, not as a secondary health check. Set alerts for lag thresholds appropriate to your use case requirements.
Treat schema changes as a change management process
Every schema change in a source database is a potential CDC incident. Establish a process where schema changes on CDC-monitored tables are communicated to the data engineering team before they are deployed to production. The CDC pipeline and downstream consumers must be updated to handle the new schema before the database change is applied, not after.
Size your log retention appropriately
If the CDC tool falls behind and the relevant portion of the transaction log is purged before the CDC engine reads it, the pipeline must perform a full re-snapshot of the source table, an expensive and disruptive operation. Set log retention to cover at least 24 hours more than your expected maximum CDC lag, with additional buffer for incident recovery time.
Common CDC challenges and how to solve them
.png)
How to evaluate and implement a CDC solution
The following framework is designed for IT decision makers leading a CDC evaluation or implementation. It covers the questions that determine success before a line of CDC configuration is written.
Step 1: define your latency requirement
The single most important input to a CDC evaluation is your actual latency requirement. Real-time (sub-second), near-real-time (seconds to minutes), or batch (minutes to hours)? This determines whether you need true log-based CDC, cursor-based replication, or whether a higher-frequency ETL job would suffice. Most organisations overestimate their real-time requirements, be honest about what the business actually needs.
Step 2: audit your source database estate
Document every database that will be a CDC source: the database engine and version, whether logical replication or log access is available, the approximate write volume per second on the target tables, and the schema complexity and change frequency. This audit determines which CDC method is available for each source and what configuration changes are required on the database side.
Step 3: assess your engineering team's Kafka readiness
Log-based CDC at scale typically involves Kafka as the messaging layer. If your team has no Kafka experience, evaluate whether a fully managed CDC platform (Fivetran, AWS DMS) can meet your requirements without the Kafka dependency. If Kafka is already part of your infrastructure, Debezium is typically the most capable and cost-effective choice.
Step 4: design the destination integration
CDC delivers change events, not updated tables. Your destination system must be designed to consume change events and apply them correctly, upserting on INSERT and UPDATE events, deleting on DELETE events, in the correct order. This consumer design is often underestimated in CDC implementations and deserves as much engineering attention as the CDC source configuration.
Step 5: plan for ongoing operations
CDC is not a set-and-forget system. Plan for schema change management, lag monitoring, on-call procedures for pipeline failures, and capacity planning as data volumes grow. Assign ownership of the CDC infrastructure clearly, ambiguous ownership of production data pipelines is a reliability risk.
Frequently asked questions about change data capture
What is change data capture in simple terms?
Change data capture is the process of tracking every change made to a database, every new row added, every existing row updated, every row deleted, and delivering those changes to other systems in near real time. Instead of copying the entire database on a schedule, CDC captures only what changed and sends it immediately. The result is downstream systems that are kept current within seconds of the source database, rather than hours.
What is the difference between CDC and ETL?
ETL copies data in bulk on a schedule, typically by querying entire tables and loading the results. It asks: what does the data look like now? CDC captures only the rows that changed, continuously. It asks: what just changed? ETL is appropriate for historical data loading and scheduled reporting. CDC is appropriate for real-time synchronisation, event-driven architectures, and use cases where data freshness is measured in seconds rather than hours. Most production data architectures use both: ETL for the initial historical load, CDC to keep data current thereafter.
What are the three methods of change data capture?
The three methods are: (1) Log-based CDC, reads the database transaction log to capture changes with zero impact on the production database and sub-second latency. This is the industry standard for production use. (2) Timestamp-based CDC, polls the database on a schedule, comparing a timestamp column to find changed rows. Simple to implement but cannot detect hard deletes and adds query load to the source. (3) Trigger-based CDC, uses database triggers to write changes to a shadow table. Captures all change types but adds write overhead to every source database operation, making it unsuitable for high-volume systems.
What are the best CDC tools in 2026?
The leading CDC tools in 2026 are: Debezium (open source, Kafka-native, industry standard for engineering-heavy teams), Fivetran (managed CDC connectors with zero infrastructure overhead), AWS DMS (managed CDC for AWS-native database migrations and replication), Airbyte (CDC connectors alongside broader data ingestion), and Informatica CDC (enterprise and mainframe CDC with governance). The right choice depends on your database ecosystem, engineering capacity, cloud environment, and whether you need a standalone CDC tool or CDC as part of a broader data integration platform.
What databases does CDC support?
Most production CDC tools support the major relational databases: PostgreSQL, MySQL, SQL Server, Oracle, and MongoDB. Debezium additionally supports DB2 and MariaDB. Informatica provides the broadest enterprise coverage including mainframe systems (IBM z/OS, HP NonStop). Support quality varies by tool and database version, always validate CDC support against your specific database engine version before committing to a platform, as log format changes between major database versions can affect compatibility.
How does CDC affect the performance of the source database?
Log-based CDC has minimal impact on source database performance because it reads from the transaction log, which the database writes regardless of CDC. The CDC tool connects as a replica reader, adding no query load to the production tables. The primary impact is on log retention storage: enabling logical replication requires the database to retain more log history than it would by default, which increases storage requirements. Timestamp-based CDC, by contrast, adds query load proportional to polling frequency. Trigger-based CDC adds write overhead to every INSERT, UPDATE, and DELETE operation on monitored tables.



