

.png)
What is data lakehouse architecture
A data lakehouse is a unified data architecture that combines the advantages of a data warehouse and a data lake. It provides high-performance, affordable, and governance-friendly storage space for various data types including structured, semi-structured, and unstructured data.
Unlike traditional approaches that require separate data lakes and data warehouse infrastructures, a data lakehouse brings them together in one platform. This eliminates the need for complex data copies and separate systems while supporting both business intelligence (BI) and machine learning (ML) workloads.
The architecture stores raw data in a range of formats from thousands to hundreds of thousands of sources in a central location. Data becomes immediately usable by integrated analytics tools for training AI models and generating reports and dashboards.
Key features that define data lakehouse architecture
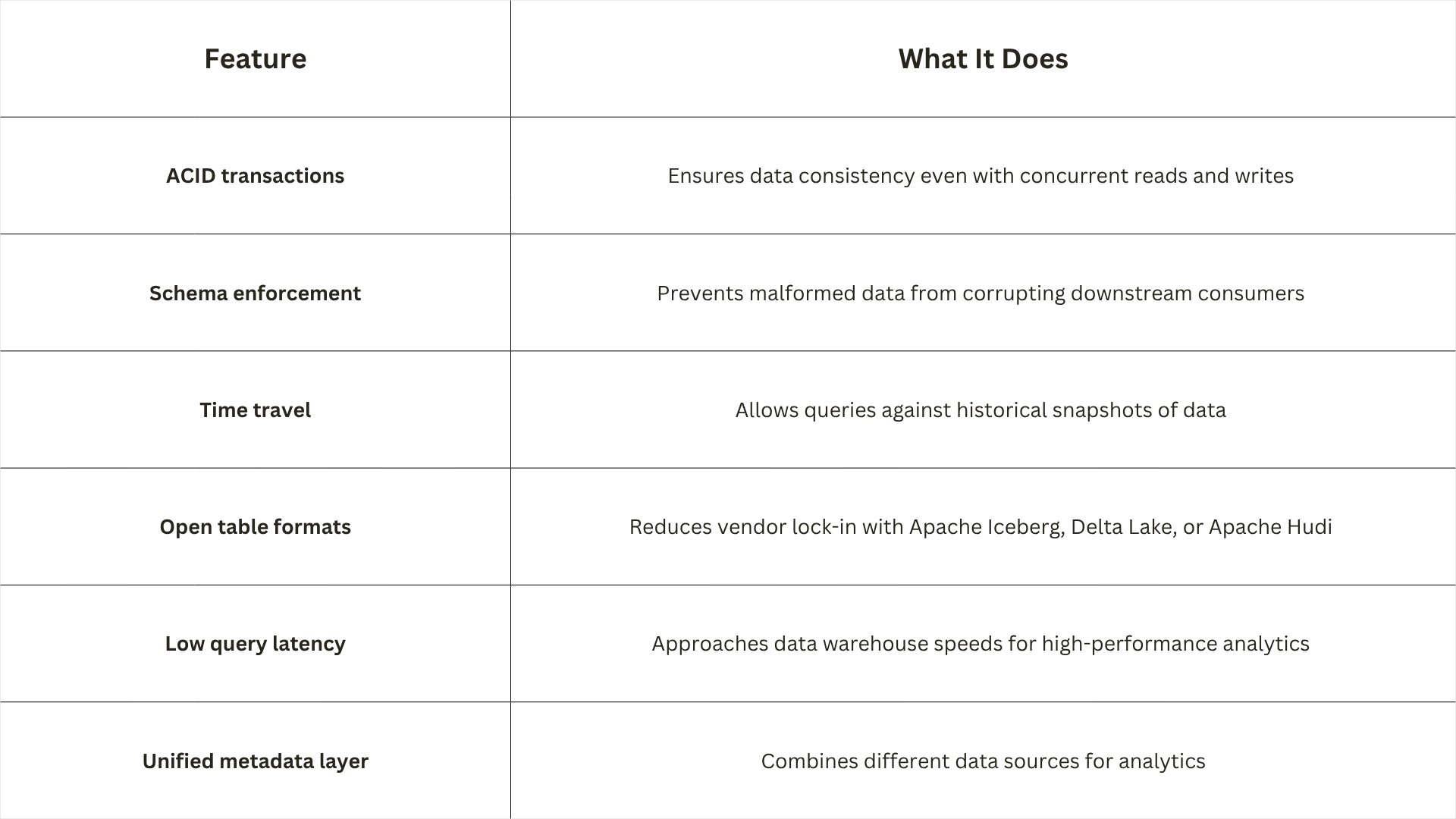
The data lakehouse has emerged as the dominant pattern in 2026, fundamentally maturing the data lake category. This architecture solves the most persistent failure modes of the original data lake design by adding transactional reliability and warehouse-grade query performance on top of cheap cloud object storage.
Three core layers of data lakehouse architecture
A data lakehouse uses low-cost cloud object storage of data lakes to provide on-demand, scalable storage for massive volumes of data in its raw form. It then integrates metadata layers over this store to provide warehouse-like performance and optimization.
The architecture consists of three core layers:
Storage layer
A low-cost object store for all raw datasets, decoupled from compute resources to allow independent scaling. This is typically AWS S3 for cloud deployments.
Staging layer
A metadata layer that provides a detailed catalog, applying management features such as indexing, caching, and access control. This layer enables schema enforcement and ACID transactions.
Semantic layer
The user-facing layer where client apps, analytics tools, and data scientists access data for experimentation and BI presentation. This is where SQL analytics and machine learning workloads converge.
This three-layer structure provides a single platform for business intelligence, predictive analytics, and generative AI workflows. By unifying siloed data, organizations avoid maintaining separate systems and complex synchronization overhead.
Medallion data architecture: The implementation pattern
Medallion Architecture is a data management framework that logically organizes data into 3 layers within a data lakehouse, bronze, silver, and gold. Each layer contains data at a different processing stage.
This pattern is frequently referred to as medallion architecture and is the recommended design approach for modern lakehouse implementations.
How data flows through medallion architecture
Raw data enters the system in the bronze layer, gets cleaned and transformed in the silver layer, and then turns into fully processed data at the gold layer. As data flows through medallion architecture, each layer stores, processes, and manages the data during a different stage in its lifecycle.
Bronze layer: The foundation
The Bronze layer is the foundation of the Medallion Architecture, where raw data first lands. Its defining characteristic is immutability, this data should never change.
Silver layer: Refined data
The data is cleaned, transformed, and structured to make it more usable for analytics and reporting. Silver is refined data that has passed quality checks.
Gold layer: Curated truth
Gold is curated business-ready data. This layer contains fully processed, business-ready data that can be modeled and analyzed.
The medallion architecture is a multi-layered data management approach for data lakehouses, where data quality gradually improves as it moves through each layer. This progressive improvement makes data more suitable for business intelligence and machine learning applications.
Apache Iceberg: The open table format for modern lakehouses
Apache Iceberg has emerged as the leader in open table formats in 2026, culminating years of development and industry competition. By 2026, it has become clear that Apache Iceberg has won the format wars.
What was once considered less performant just a few years ago has now become the industry standard, backed by major technology companies and enjoying widespread adoption.
Why Iceberg data lakehouse dominates 2026
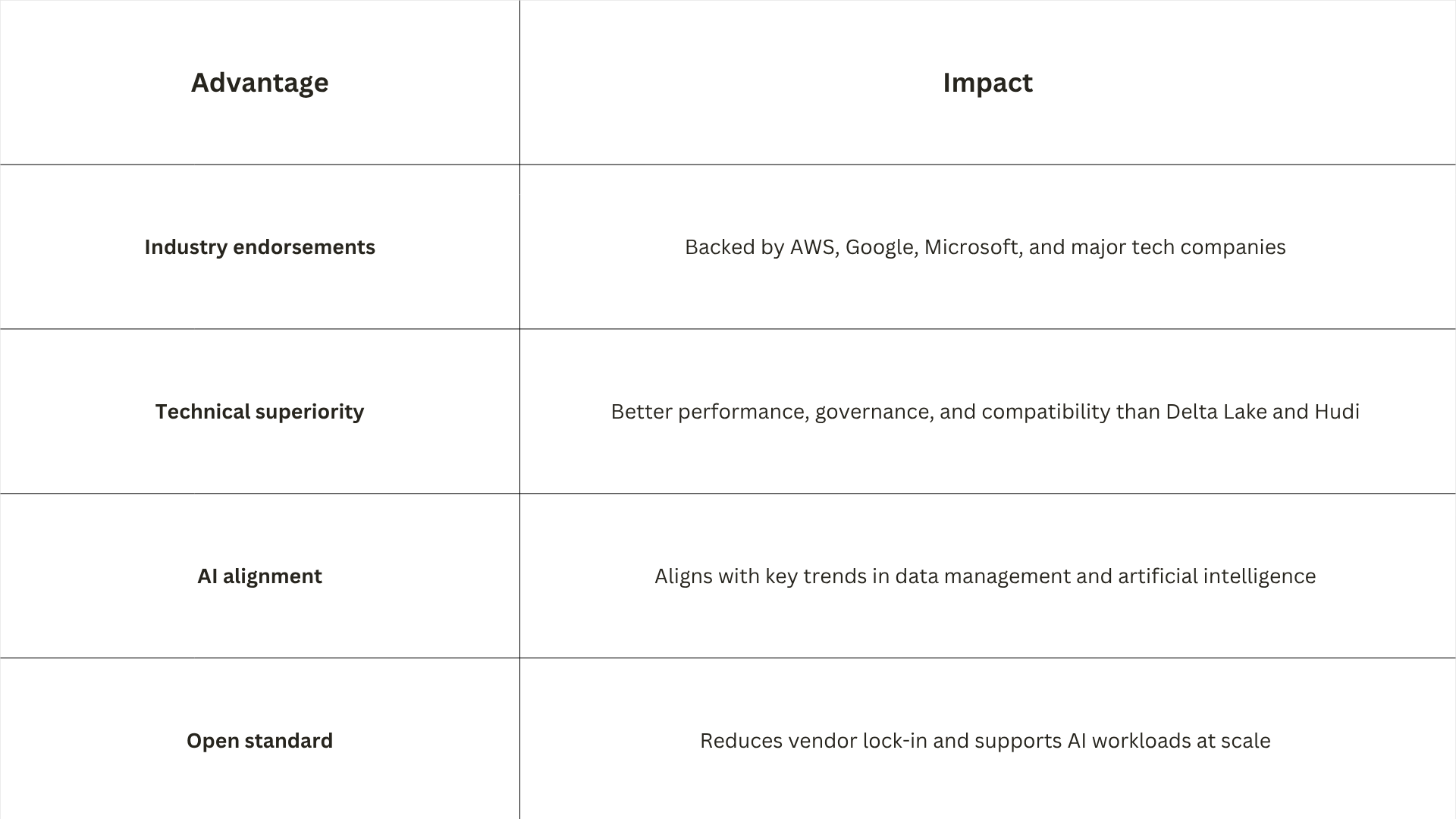
Apache Iceberg has moved beyond early adoption and into the core of enterprise data platforms. It is now widely used to support large-scale analytics, AI and ML workloads, and business-critical reporting across modern lakehouse environments.
The next generation of Amazon SageMaker is built on an open lakehouse architecture, fully compatible with Apache Iceberg. Apache Iceberg in combination with supported AWS services enables a transactional data lake, often based on storage in S3.
Key Iceberg features for enterprise deployments
- ACID guarantees ensure data consistency
- Time travel enables queries against historical snapshots
- Schema evolution allows table structure changes without data reload
- Partition evolution supports performance optimization over time
Data lakehouse market growth and enterprise adoption
The Data Lakes Market reached an estimated USD 20.18 billion in 2025 and is projected to climb to USD 24.62 billion in 2026. The market will surge to USD 148.50 billion by 2035, registering a CAGR of 23.50% over the 2026–2035 forecast window.
Cloud deployment held the majority share of the Data Lakes Market in 2025, valued at approximately USD 13.70 billion. North America dominated the Data Lakes Market with a 40.10% share in 2025.
Market trajectory by deployment type
Hybrid and multi-cloud architectures are forecast to grow at a 24.60% CAGR to 2035 as organizations pursue multi-cloud portability strategies.
Solutions captured roughly 73% of revenue in the Data Lakes Market in 2025, reflecting strong demand for integrated platforms supporting Apache Spark processing for data lake analytics. Services are poised to expand at a 26.40% CAGR through 2035 as enterprises seek managed deployment and data lake governance consulting.
The global data lake market size was USD 11.07 billion in 2025 and is projected to expand to USD 84.27 billion by 2034, growing at a CAGR of 25.30%.
Why organizations choose data lakehouse implementation
A data lakehouse combines the openness and scalability of data lakes with the reliability and governance of data warehouses in a single platform. By keeping all data in one place and supporting both BI and advanced analytics, a lakehouse removes the need for separate systems and complex data copies.
Business benefits of data lakehouse architecture
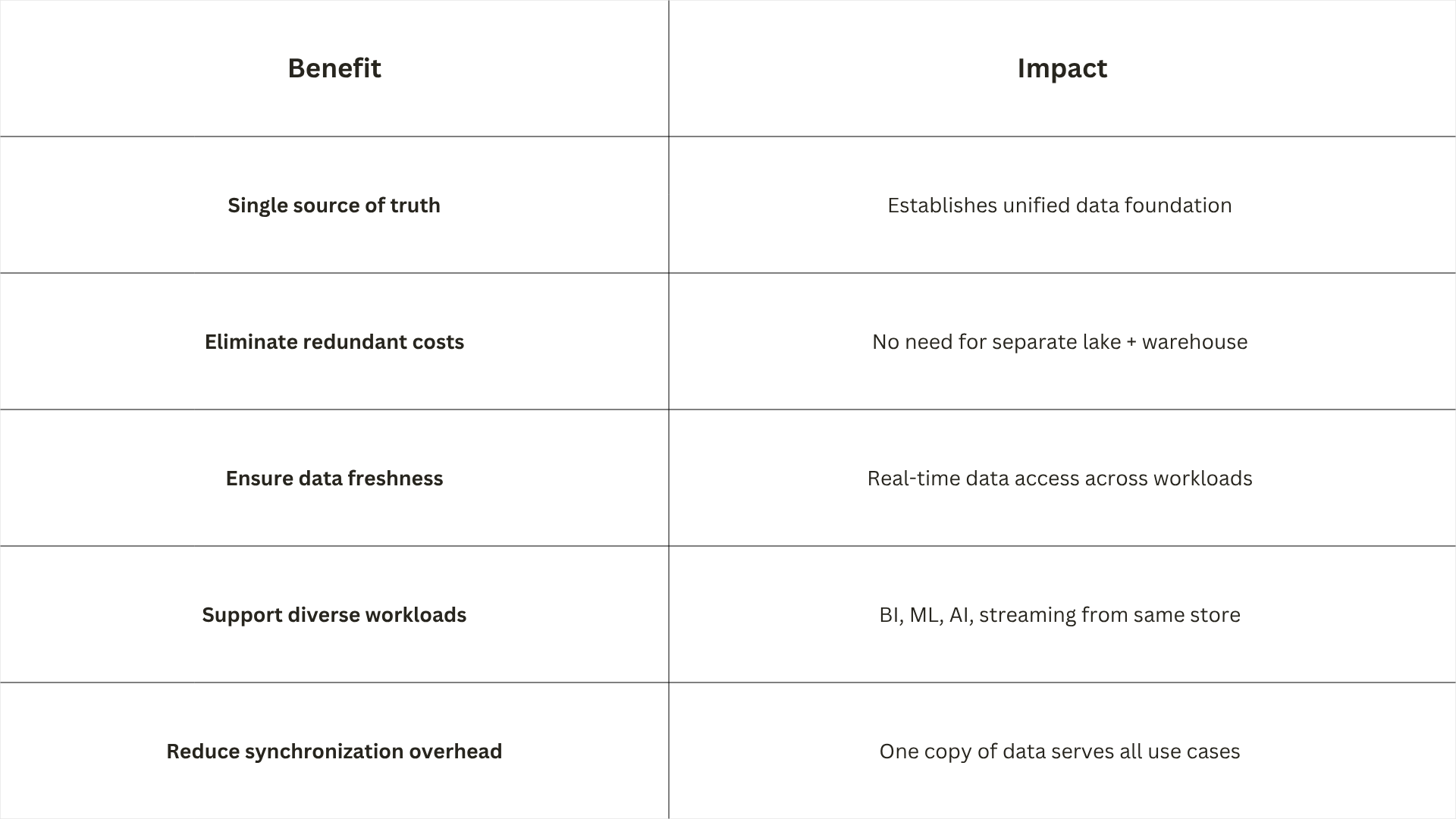
Data lakehouses provide scalable storage and processing capabilities for modern organizations that want to avoid isolated systems for processing different workloads like machine learning and business intelligence.
The data lakehouse combines the benefits of data lakes and data warehouses and provides open, direct access to data stored in standard data formats. It offers indexing protocols optimized for machine learning and data science, plus low query latency and high reliability for BI and advanced analytics.
By combining an optimized metadata layer with validated data stored in standard formats in cloud object storage, the Data Lakehouse allows you to work from the same data and in the same platform across different use cases.
How LakeStack implements data lakehouse architecture on AWS
LakeStack is a no code, AWS native data platform that unifies data lakes, ETL pipelines, BI, and AI into one plug and play stack. It deploys AI-ready, governed data infrastructure directly into your own AWS account in under 2 weeks.
LakeStack's data lakehouse implementation approach
LakeStack deploys directly into your own cloud (built on AWS) so you own and control your data. This means no data leaves your AWS account and you maintain full governance control.
Medallion architecture in LakeStack
LakeStack implements medallion data architecture with Bronze, Silver, and Gold layers automatically configured. Raw data lands in Bronze, gets cleaned in Silver, and becomes business-ready in Gold, all managed through AWS Glue pipelines.
This progressive data refinement makes information more suitable for business intelligence and machine learning applications without manual pipeline construction.
Apache Iceberg integration
LakeStack uses Apache Iceberg as its open table format, providing:
- ACID transactions for data consistency
- Time travel for historical queries
- Schema evolution for flexible table structure changes
- Full compatibility with AWS SageMaker's open lakehouse architecture
Apache Iceberg powers both batch and real-time data pipelines in LakeStack, enabling consistent, low-latency data access across all workloads.
AWS Glue optimization for lakehouse
LakeStack leverages AWS Glue for ETL with Iceberg-specific optimizations:
- S3 Table Buckets for managed Iceberg table maintenance and storage optimization
- Materialized views in Glue to pre-compute aggregates and boost query performance
- Catalog management and federation to enable agile, cross-source analytics
- Iceberg integration with AWS compute services like Athena, Redshift, and EMR Spark
AWS Glue Iceberg views offer valuable benefits by reducing data pipeline complexity and delivering results quickly.
Real-time data lakehouse implementation on AWS
Modern lakehouse implementations enable real-time data pipelines alongside traditional batch processing. In one implementation using AWS Glue and Iceberg, teams built a real-time pipeline that ingests, enriches, and aggregates streaming sales data directly into a lakehouse.
Real-time pipeline architecture pattern
HTTP Endpoint → Iceberg Bronze → Postgres Lookup → Iceberg Silver → Aggregate → Iceberg Gold
This pattern includes:
- HTTP Endpoint source for continuously ingesting sales events
- Iceberg Sink for writing bronze layer raw sales records
- Postgres lookup enricher for getting product data
- Iceberg Sink for writing silver layer enriched records
- Aggregate component for stateful computation of real-time metrics
- Iceberg Sink for writing gold layer sales aggregates
LakeStack supports this same real-time pattern natively, eliminating the need to build custom pipelines from scratch.
Best practices for data lakehouse implementation on AWS
AWS re:Invent 2025 recommendations
Significant reduction in data latency and improved data consistency come from following these best practices:
- Use S3 Table Buckets for all Apache Iceberg projects if possible, and size files appropriately
- Set up snapshots and partitioning to ensure performance into the future
- Leverage materialized views for pre-aggregated, pre-computed results
- Prioritize catalog management to enable agile, cross-source analytics
- Integrate Iceberg with AWS compute services like Athena, Redshift, and EMR Spark
Medallion architecture best practices
When implementing medallion architecture in AWS, follow these patterns:
- Use one workspace per medallion layer for clear separation
- Inside each workspace, use one lakehouse per data source
- Combine sources in silver layer before curating to gold
- Gold layer = business-ready data for semantic models
Bonus tip: Use schemas inside lakehouses to separate domains (e.g., sales, finance) if you want fewer lakehouses.
Don't overbuild your medallion architecture
Most teams implement Bronze, Silver, Gold without asking if the dataset is actually complex enough to require three physical layers. Before automatically building three schemas, consider:
- How often does the source schema change?
- Are multiple teams modifying the structure?
- Is this shared infrastructure across multiple domains?
If the answer is no, you might not need physical separation three times. Layers should represent responsibility and boundaries, not habits.
AI readiness and data lakehouse architecture
78% of organizations reported using AI in 2024, up from 55% the year before. However, only 13% of organizations are AI Pacesetters, leaders who architect differently and deploy AI at the scale and speed needed to realize value.
The critical evolution of 2026 is the near-universal adoption of the lakehouse architecture, which solves the most persistent failure modes of the original data lake design. This architecture is essential for AI readiness because it:
- Provides open, direct access to data stored in standard formats for ML training
- Offers indexing protocols optimized for machine learning
- Supports generative AI workflows from the same underlying data store
- Enables consistent, low-latency data access for both batch and real-time AI pipelines
Apache Iceberg, Polaris, Parquet, and Arrow all pushed forward in 2025 with practical features that improve performance, governance, or compatibility. Together, they form a foundation for a warehouse experience on open data that enables AI workloads at scale.
LakeStack positions itself as the AI-ready data foundation you own precisely because it combines lakehouse architecture with Apache Iceberg and native AWS AI services.
When to choose data lakehouse over traditional architectures
Data lakehouse vs data warehouse
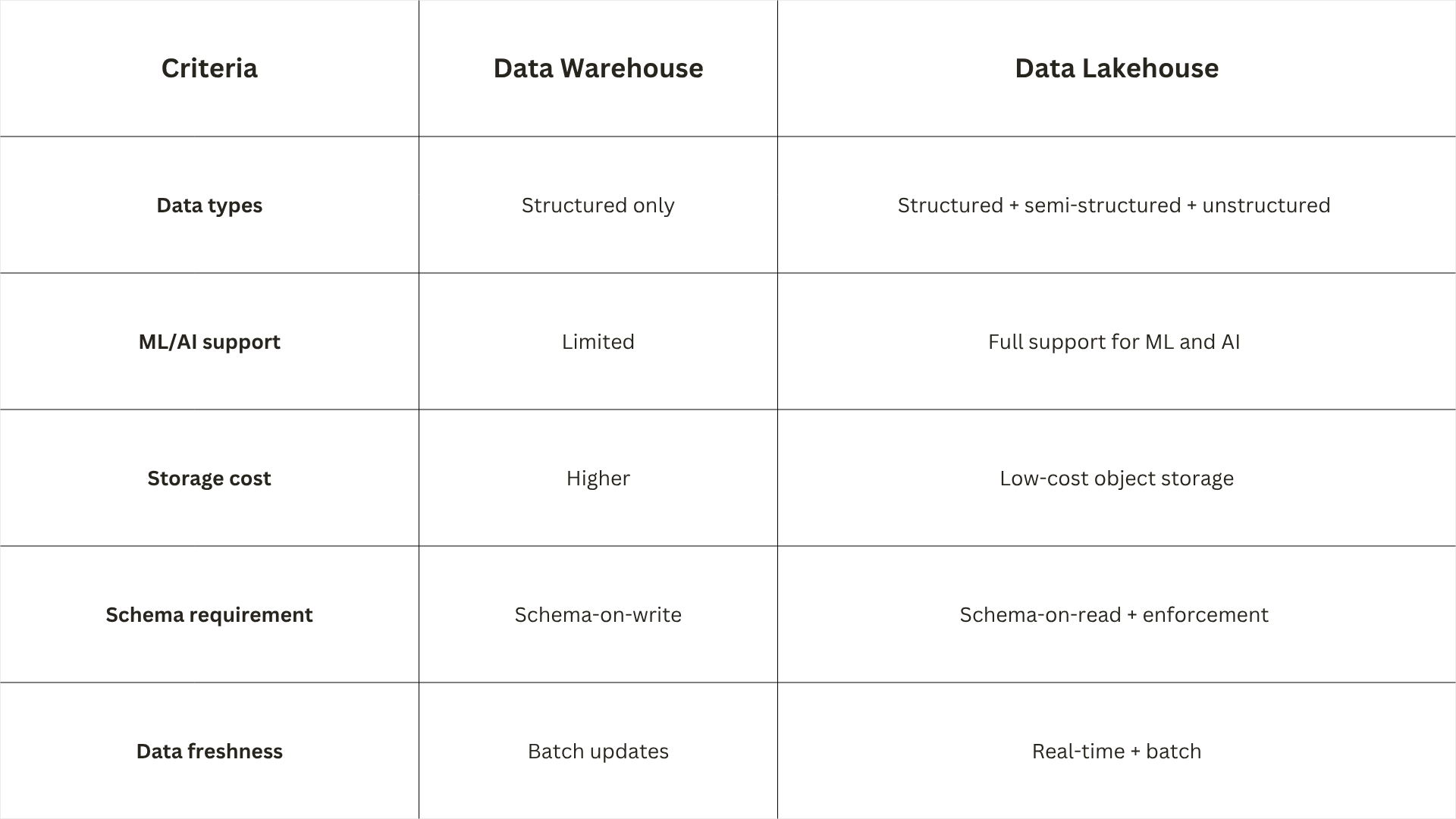
Unlike a data warehouse, a data lakehouse can store all types of semi-structured and unstructured data for machine learning purposes.
Data lakehouse vs data lake
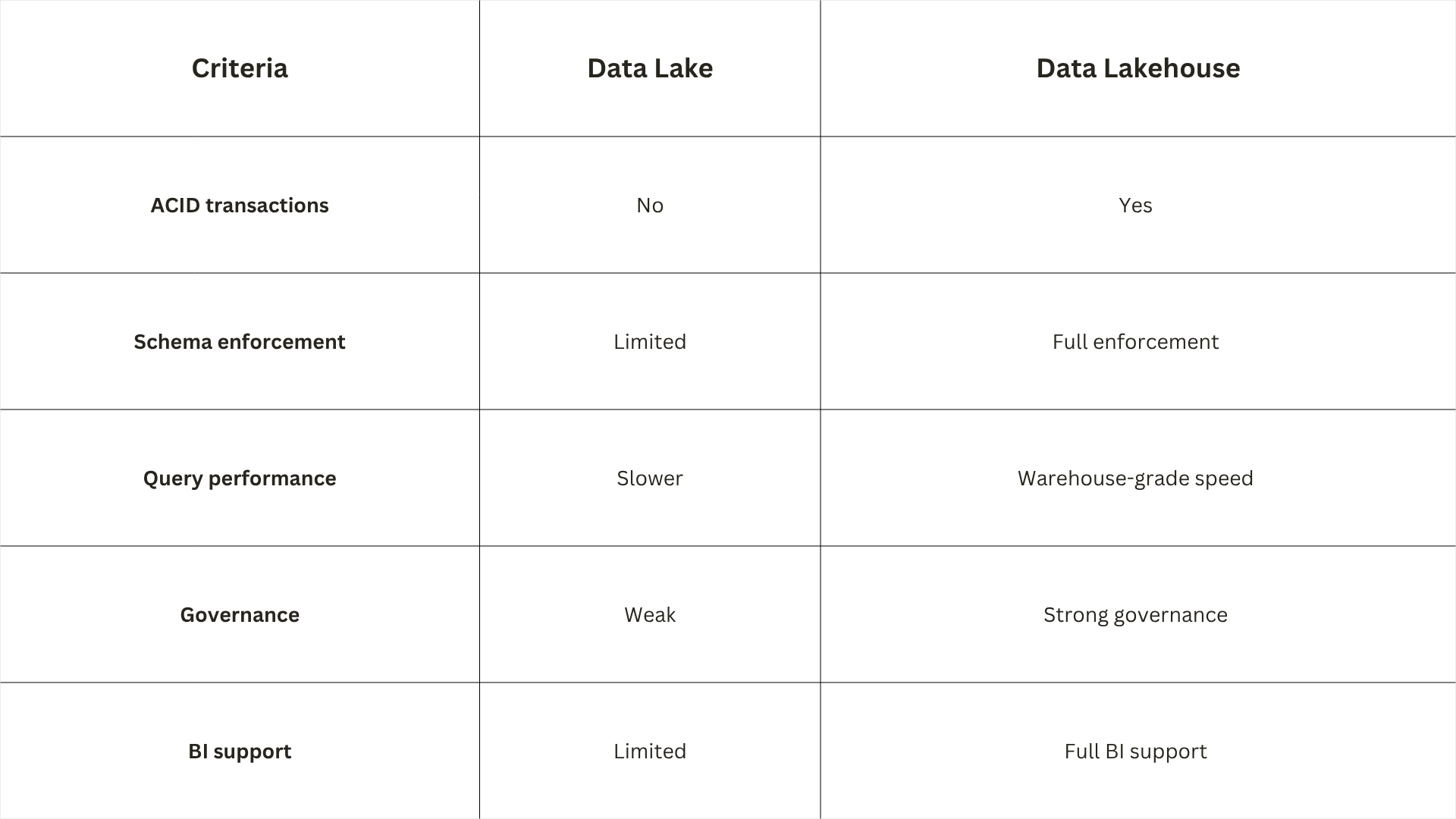
The original promise of cheap, flexible storage has been fulfilled, and the architecture has evolved well beyond it. The modern data lakehouse adds transactional reliability, governance, and warehouse-grade query performance to the economics of object storage.
Start your data lakehouse implementation with LakeStack
LakeStack unifies data lakes, ETL pipelines, BI, and AI into one plug-and-play stack deployed in your AWS account. You get AI-ready, governed data infrastructure in under 2 weeks without writing code.
What you get with LakeStack
- Complete data lakehouse architecture with Bronze, Silver, Gold layers
- Apache Iceberg integration for ACID transactions and schema evolution
- AWS Glue ETL pipelines optimized for lakehouse performance
- Medallion architecture automatically configured
- AI readiness with native AWS SageMaker compatibility
- Full ownership: data stays in your AWS account
The data lake category has matured decisively in 2026, and the lakehouse architecture is now the dominant pattern. Enterprise data teams can have the economics and flexibility of a data lake alongside the performance and reliability of a data warehouse without choosing between them or paying for both.
Ready to implement data lakehouse architecture on AWS? LakeStack deploys the complete stack in your account so you own and control your AI-ready data foundation.



