

.png)
In modern data platforms, the choice between Lambda and Kappa architecture is not a purely technical preference. It affects how quickly teams ship features, how reliably data products serve decisions, and how much effort it takes to keep batch and streaming systems in sync. If your organization is moving toward domain-owned data products, federated governance, and self-service analytics, the architecture you choose can either accelerate that shift or quietly slow it down. That is why this decision matters for both platform teams and business stakeholders.
What Lambda architecture is
Lambda architecture is a hybrid data-processing pattern that combines batch processing with real-time stream processing and a serving layer. The batch layer processes all historical data to produce accurate, comprehensive views, while the speed layer handles incoming events for low-latency results. This design was created to balance correctness and freshness in systems that need both.
The main advantage of this model is resilience in the face of changing data and business rules. When data definitions evolve, the batch layer can recompute history and correct downstream views without waiting for the live pipeline to catch up. That makes Lambda attractive for organizations that need both auditability and near-real-time delivery. Financial systems, regulated reporting, and compliance-heavy workflows often benefit from this dual-path safety.
The downside is complexity. Teams typically maintain two processing paths, two sets of operational concerns, and a serving layer that must reconcile outputs from both streams. Over time, that can increase development effort, testing burden, and the risk of inconsistencies between batch and speed results. Several teams report that the serving layer becomes a hidden source of bugs because it has to merge two different views of the same data.
In practice, Lambda architecture looks like this: ingestion into both a batch store and a streaming engine, periodic batch transformations, continuous event processing, and a serving layer that exposes a unified view to downstream users. This gives enterprises flexibility, but it also means more orchestration and more places for drift to appear. Without strong observability and ownership, the dual-path design can become brittle.
What Kappa architecture is
Kappa architecture removes the separate batch path and uses one stream-processing pipeline for both real-time delivery and historical reprocessing. Instead of recomputing through a distinct batch system, teams replay events from the log when they need to rebuild state or correct logic. That single-path design is the reason many modern teams prefer Kappa.
Kappa is designed to maximize simplicity and stream-native execution. It reduces duplicated logic, simplifies troubleshooting, and makes the platform easier to operate at scale. For organizations that already think in event streams, Kappa often feels more natural than a dual-layer approach. You do not need to maintain two processing models or worry about drift between them.
Kappa is also a better fit when low latency is a primary requirement. Systems such as fraud detection, product telemetry, operational alerts, personalization pipelines, and continuous monitoring workflows often benefit from one continuous flow of events rather than a split batch and speed architecture. If your business is fundamentally event-driven, Kappa gives you a cleaner core model.
The main tradeoff is that Kappa depends on durable event retention and strong engineering discipline around schema evolution and state management. If your stream processor is not strong enough to handle replay, late-arriving data, or complex stateful computations, the simplicity of the model can be deceptive. The best architecture is the one your team can operate consistently, not just the one that sounds elegant.
Lambda vs Kappa architecture
The real difference is not just the number of layers. It is the operating philosophy behind the pipeline. Lambda is designed to blend correctness with freshness, while Kappa is designed to maximize simplicity and stream-native execution. Lambda gives you a safer path when the business needs both historical recomputation and live results from the same source data. Kappa gives you a cleaner path when the stream itself is the source of truth and replay can handle correction.
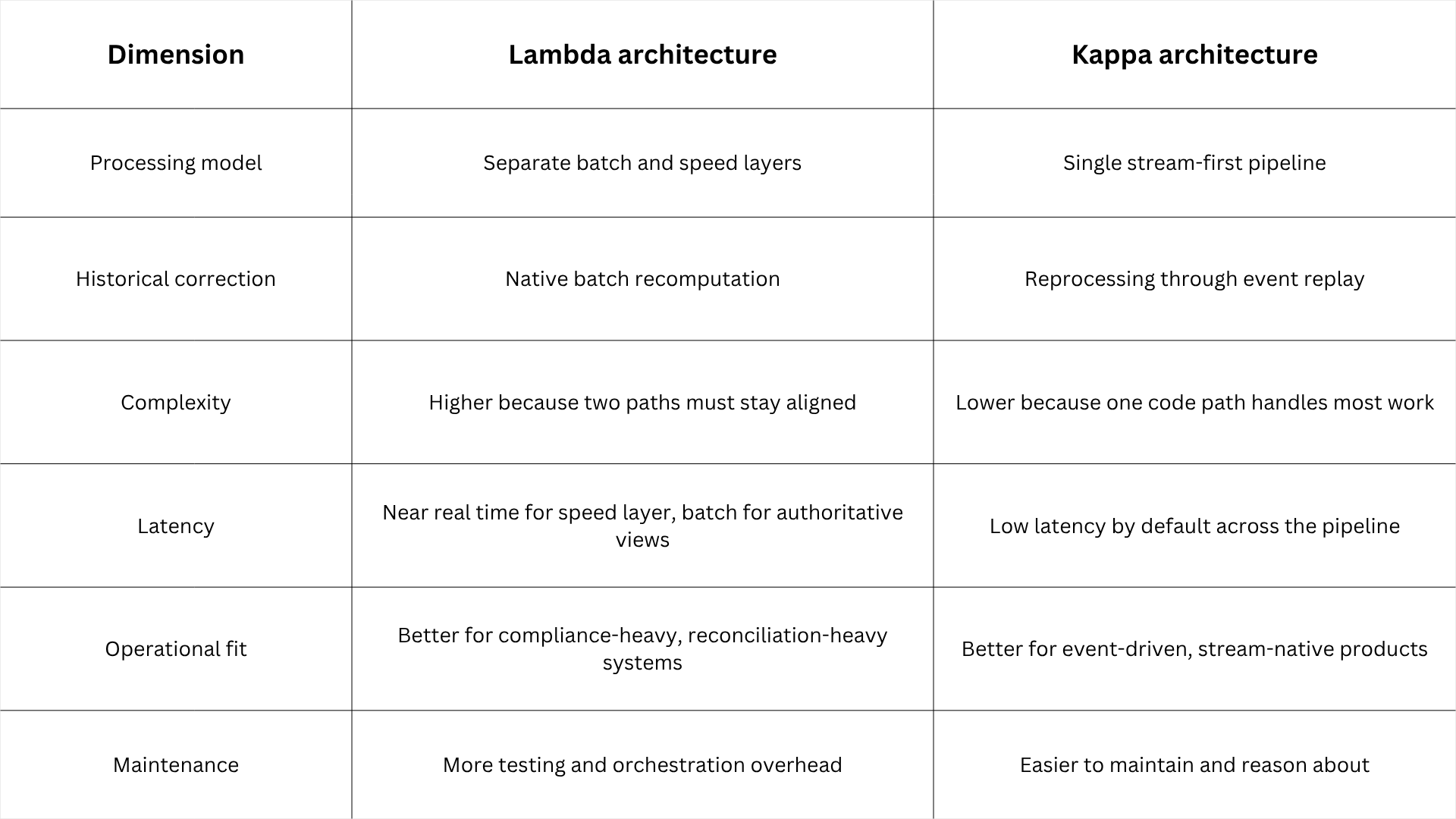
A useful way to think about it is this: Lambda optimizes for having two answers, one fast and one fully recomputed, while Kappa optimizes for having one answer that can be rebuilt from the stream. In practice, that distinction drives cost, team structure, and governance design. If your organization values operational simplicity and wants to reduce duplicated code, Kappa is usually the better default. If your organization values dual-path correctness and historical safety, Lambda may still be justified.
How the two patterns work
Lambda usually starts with ingestion into both a batch store and a streaming engine. The batch layer builds periodic datasets, the speed layer processes fresh events, and the serving layer exposes a unified view to downstream users. This gives enterprises flexibility, but it also means more orchestration and more places for drift to appear.
Kappa starts with an append-only event log and uses a single stream processor to derive outputs. If logic changes or state needs to be rebuilt, the system replays the log instead of invoking a separate batch job. That model is elegant, but it depends on durable event retention and strong engineering discipline around schema evolution and state management.
Both approaches can work well. The right one depends on whether your data system is fundamentally a hybrid warehouse plus stream platform, or a stream-native backbone that occasionally needs historical replay. Your existing technology stack, team maturity, and business constraints often determine which model is more practical.
Where Lambda architecture fits best
Lambda architecture is still relevant in regulated industries, large enterprises, and legacy environments where batch reconciliation is not optional. If finance, insurance, or compliance teams need a repeatable historical calculation layer alongside real-time dashboards, Lambda can offer the right balance of control and freshness. It also helps when data quality logic changes frequently. Because the batch layer can rebuild history, teams can correct past outputs without redesigning the streaming pipeline.
That is especially useful when business definitions are still stabilizing. In environments where regulatory rules change, Lambda gives teams a predictable way to update historical calculations without breaking live operations. The tradeoff is that Lambda tends to work best when the organization has enough platform maturity to manage multiple layers cleanly. Without strong observability and ownership, the dual-path design can become brittle.
Lambda also fits when your infrastructure is already built around batch warehouses and separate streaming engines. If you have a mature data warehouse, a batch orchestration framework, and a streaming engine that teams already know, adapting Lambda may be simpler than re-architecting everything into a single pipeline.
Where Kappa architecture fits best
Kappa architecture is often the stronger choice for new data products that are event-driven from day one. If your team is building operational analytics, customer-facing personalization, sensor-driven systems, or continuous monitoring workflows, Kappa usually gives you the lowest-friction path. It also aligns well with modern engineering teams that prefer fewer architectural abstractions. One pipeline is easier to test, deploy, secure, and explain than two separate processing layers.
That simplicity becomes valuable as the number of domains and use cases grows. Another advantage is that Kappa tends to reduce duplicated logic between batch and streaming code. That can improve maintainability and shorten the feedback loop for product teams. For many organizations, that alone is enough to justify the switch.
Kappa also fits organizations that are already invested in event logs like Kafka or Pulsar and want a unified stream processor like Flink or a similar engine to handle both live and historical workloads. In those environments, replaying the log is a natural pattern, and the extra batch layer in Lambda can feel redundant.
Data mesh alignment
Data mesh introduces a decentralized operating model where domains own their data products and governance is federated across the organization. In that world, the architecture must support autonomy without creating chaos. Kappa often fits data mesh more naturally because stream-first platforms can serve domain products from a shared event backbone while preserving team ownership. It is easier for domain teams to publish and evolve event-driven products when they are not also managing separate batch semantics.
Lambda can still work in a data mesh environment, but the dual-path setup raises the coordination cost between platform and domain teams. If the organization already struggles with duplicated logic or unclear ownership, Lambda can make those problems more visible rather than solving them. In a data mesh, simpler operational patterns are usually more sustainable over time.
The four core data mesh principles are domain-oriented decentralized ownership, data as a product, self-serve data platform, and federated computational governance. An architecture that supports those principles with minimal friction is more likely to succeed at scale. Kappa tends to align more directly with those goals, while Lambda requires more intentional design to avoid becoming a bottleneck.
Cost and complexity tradeoffs
Architecture decisions always have a financial side. Lambda often requires more infrastructure, more orchestration, and more engineering time because two processing layers must be designed, tested, and observed. That can increase platform cost even when the business value is justified. Teams must maintain batch orchestration, streaming orchestration, storage for both layers, and a serving layer that reconciles outputs. They also need monitoring for drift between the two views.
Kappa usually lowers that overhead by collapsing the problem into one continuous processing path. Less duplication means fewer moving pieces, and fewer moving pieces usually means lower maintenance burden. Development velocity often improves because engineers only need to understand and maintain one pipeline. Testing becomes simpler because there is no need to validate consistency between batch and speed outputs.
That said, Kappa is not free. If your stream processor is not strong enough to handle replay, late-arriving data, or complex stateful computations, the simplicity of the model can be deceptive. You May need to invest in better event retention, better schema management, and more careful state design. The best architecture is the one your team can operate consistently, not just the one that sounds elegant.
Reliability and governance
Governance is where architecture becomes operational reality. In Lambda, data governance has to span both batch and streaming paths, which can make lineage, quality checks, and access controls more complex. You must track transformations in two systems and ensure that policies are enforced consistently. In Kappa, governance can be enforced closer to the event backbone, which may simplify policy implementation. Lineage becomes more straightforward because there is one derivation path.
For enterprise teams, this matters because governance is increasingly tied to trust, not just compliance. If users cannot understand where a metric came from or which transformation produced it, they will hesitate to use the data product. A good governance model should also support observability, schema evolution, and ownership clarity. Those capabilities are easier to standardize when the pipeline architecture is simple and domain responsibilities are explicit.
In a data mesh environment, federated governance is critical. You want domain teams to own their data products without creating policy violations. A simpler architecture like Kappa can make it easier to define and enforce governance rules at the event backbone, while still allowing domain teams to innovate on top of it.
Decision framework
Use Lambda architecture when you need both real-time responsiveness and a strong batch recomputation layer, especially in environments where historical accuracy must be authoritative. Choose it if your business depends on reconciling live and historical data, and if your team can support the extra operational complexity. Lambda is also a good bridge when you have a mature batch warehouse and a separate streaming engine that teams already use.
Use Kappa architecture when your platform is stream-native, your data is event-driven, and your team values a simpler operational model. Choose it if replayable logs and modern stream processors can meet your historical correction needs without a separate batch system. Kappa is especially attractive when you are building new data products from scratch or migrating from a legacy batch system to a modern event-driven platform.
A practical test is to ask whether batch exists because the business truly needs it, or because the current stack grew that way over time. If the latter is true, Kappa may be the cleaner long-term design. Another test is to evaluate whether your team can handle the coordination overhead of two processing paths. If that is a challenge in your environment, Kappa is likely safer.
LakeStack implementation angle
For LakeStack, the architectural conversation should be tied to product outcomes. If the platform aims to unify ingestion, transformation, governance, and analytics into a streamlined data foundation, a Kappa-style approach usually fits the story of a modern, governed, AI-ready stack better. This aligns with positions that emphasize no-code, AWS-native, and AI-ready data platforms.
That does not mean Lambda is obsolete. In complex enterprises, especially where historical reconstruction and compliance are central, a Lambda-inspired design can still be the right bridge from legacy operations to modern streaming. The value of LakeStack is in helping customers choose the right operating model and then standardize it. You can support both patterns, but the default should be the simpler one unless there is a clear justification for the complex one.
This is also where internal linking can support conversion. Relevant anchors could point to product pages for data ingestion, governance, transformation, and platform overview, especially when the article explains how architecture affects operational simplicity and business agility. If you mention LakeStack as a modern, governed, AI-ready foundation, you can link to the product overview page. If you discuss ingestion and event logs, you can link to ingestion capabilities. If you discuss governance and data products, you can link to governance features.
Real-world examples
A retailer building live inventory alerts, demand signals, and customer personalization may prefer Kappa because a single event backbone can drive all three use cases. The team can replay events if needed, but the day-to-day emphasis stays on low-latency processing. This pattern is common in product telemetry and customer experience systems.
A bank producing regulatory reports, risk metrics, and customer-facing dashboards may still choose Lambda if reconciliation and historical recomputation are mandatory. In this case, the batch layer protects correctness while the speed layer supports timely decisions. This pattern is common in financial reporting and compliance systems.
A healthcare platform supporting clinical operational analytics may land somewhere in between. If the use case includes both streaming alerts and auditable historical recordkeeping, a hybrid path can still be justified. This is especially true where HIPAA compliance and auditability are critical.
Common mistakes to avoid
Assuming Kappa is always simpler in every sense
Kappa removes the duplicate batch layer, but it does not remove complexity. It shifts that complexity into the event log and the stream processor. Teams must design clean event models, keep schemas stable, and ensure that every transformation can be replayed safely. If a team underestimates schema evolution, late-arriving events, or state management, the Kappa system can become harder to operate than expected. In practice, this means you need strong discipline around:
- Event naming and structure that stay consistent over time
- Schema versioning that does not break existing consumers
- Idempotent transformations that can be replayed without side effects
- State backends that can handle large histories and frequent replays
- Monitoring and alerting that catch replay failures and data drift early
Without these practices, Kappa can look simple on paper but become fragile in production.
Choosing Lambda just because batch processing feels safer
Many teams keep Lambda because they started with a batch warehouse and never revisited the assumption that they need a separate batch layer. This is a habit, not a requirement. If your business does not truly need separate batch semantics, Lambda can create unnecessary cost and maintenance load. The extra overhead of Lambda includes:
- Two orchestration pipelines (batch and streaming) that must stay aligned
- Two storage systems that often duplicate data
- A serving layer that must reconcile different views of the same data
- More testing to ensure consistency between batch and speed outputs
- More operational complexity to monitor drift and fix mismatches
If your use cases are mostly event-driven and your stream processor can handle replay, Kappa is often the cleaner long-term design. Before committing to Lambda, ask whether the batch layer is truly needed for business correctness or just inherited from legacy architecture.
Ignoring governance until after the pipeline is built
Governance is too critical to treat as a later phase. Whether you choose Lambda or Kappa, ownership, lineage, and quality checks should be designed with the architecture, not added later. Governance is part of the design, not a phase that comes after. Common governance pitfalls include:
- No clear owner for a data product, so multiple teams change it independently
- Lineage that is not tracked, making it hard to explain how a metric was computed
- Quality checks that only run in one layer, leaving gaps in the other
- Access controls that are applied inconsistently across batch and streaming paths
- Schema changes that are not validated against downstream consumers
In a data mesh environment, these problems become more visible. Domain teams need clear ownership and federated governance so they can innovate without creating policy violations. If governance is missing from the start, fixing it later often requires reworking pipelines, retraining teams, and rewriting logic. A better approach is to define governance as part of the initial architecture:
- Define data product owners and their responsibilities upfront
- Track lineage from ingestion to consumption in a single model
- Implement quality checks that run on both batch and streaming data (if using Lambda) or on the unified stream (if using Kappa)
- Standardize access controls and policy enforcement at the event backbone or serving layer
- Treat schema changes as controlled events with validation and consumer approval
When governance is built in from the start, the architecture becomes more trustworthy, more auditable, and easier to scale across domains.
Final recommendation
For most modern teams, Kappa architecture is the better default because it reduces complexity, supports real-time processing, and aligns well with event-driven platform design. That is especially true when the broader strategy includes data mesh, where domain ownership and streamlined data products matter. Kappa gives teams a cleaner operational model and a more sustainable path as use cases scale.
Lambda architecture remains valuable when the business genuinely needs separate batch recomputation and streaming delivery, or when compliance and historical reconciliation are core requirements. In other words, Lambda solves a harder operational problem, while Kappa solves a cleaner one. The best choice is the one that fits your data stack, your governance model, and the maturity of your platform team.
If your architecture supports the way your organization actually works, it will scale far better than any pattern chosen for trend value alone. Use Lambda when you truly need dual-path correctness. Use Kappa when you can rely on replay and want a simpler, stream-native foundation. Let your business constraints, team capabilities, and existing stack guide the decision, not industry hype.

.png)
