


Enterprises are generating more data than ever, but data volume alone does not create intelligence. The real challenge is turning fragmented, constantly changing information into answers that are accurate, explainable, and safe to use in production. That is where retrieval-augmented generation, or RAG, becomes essential: it grounds model outputs in enterprise data instead of relying only on pretrained model memory.
LakeStack and Amazon Bedrock together provide a practical path to production RAG on governed data. LakeStack brings structure, security, and data stewardship to the lakehouse foundation, while Bedrock gives teams managed orchestration for retrieval, embeddings, and response generation. When paired with a vector database, this architecture supports semantic search, access control, and scalable AI delivery without sacrificing governance.
Why RAG needs governance
Standalone LLMs are powerful, but they can still produce outdated or fabricated answers when they are disconnected from enterprise systems. RAG reduces that risk by retrieving relevant context at query time and injecting it into the prompt, which improves factual grounding and response relevance.
In enterprise settings, that is only half the problem. The other half is ensuring that the retrieved content is allowed, current, traceable, and auditable. If a model can retrieve the wrong document, the wrong version, or data a user should not see, the architecture fails even if the answer sounds convincing. That is why governed data platforms matter as much as the model itself.
LakeStack is especially relevant here because it provides a controlled data foundation rather than a loose collection of object storage and ad hoc pipelines. With S3 Access Grants and IAM Identity Center-aligned access patterns, organizations can scope access at the bucket, prefix, or object level, which fits the needs of multi-team enterprise AI use cases.
Why vector databases matter
Vector databases are the retrieval engine behind modern RAG systems. They convert documents, tickets, notes, code, policies, and other content into embeddings that encode semantic meaning, enabling similarity search beyond exact keywords.
That matters because users rarely ask questions using the exact terms that appear in a source document. A vector store can recognize that “vendor onboarding policy,” “third-party approval process,” and “supplier intake rules” may refer to the same concept. In practical terms, this creates much better recall than keyword search alone, especially for long-form enterprise content.
The best production systems rarely use vectors by themselves. They combine dense vector retrieval with keyword search, metadata filters, and authorization checks to improve precision and enforce access boundaries. That hybrid pattern is a major reason OpenSearch Serverless is frequently chosen for Bedrock-powered retrieval workloads.
Vector database use cases
Vector databases are useful across nearly every enterprise function. In knowledge management, they let employees ask natural-language questions over policies, operational playbooks, research repositories, and project archives, then receive sourced answers from governed content.
Customer support teams use them to retrieve the most relevant product documentation, prior ticket resolutions, and troubleshooting guidance. Financial services teams apply them to contract review, due diligence, policy comparison, and compliance analysis, often with strict filters that control which records are eligible for retrieval. Healthcare and life sciences organizations use vector search to assist with document-heavy workflows while maintaining privacy and access restrictions.
They are also foundational for agentic AI. Agents need memory, context, and a way to reason over large bodies of dynamic information. A governed vector database gives them semantic access to enterprise knowledge without exposing the full underlying corpus indiscriminately.
AWS options for RAG
AWS provides several backend choices for Bedrock knowledge bases and vector-driven search workloads. Amazon OpenSearch Serverless is a common default because it supports vector search, keyword search, and hybrid retrieval while removing much of the operational burden of cluster management.
Amazon Aurora PostgreSQL with pgvector is a good fit for teams that want SQL-native workflows or already rely heavily on relational data platforms. Amazon Neptune Analytics is valuable when graph relationships matter alongside semantic retrieval, such as in lineage, fraud, or entity-linked discovery use cases. AWS also now supports S3 Vectors with Bedrock Knowledge Bases, which can simplify and reduce vector storage costs for RAG applications.
For most enterprises, the decision is not simply “which database is best,” but “which backend best matches the workload.” If the priority is low-ops simplicity, Bedrock-managed retrieval is attractive. If the priority is sustained QPS, hybrid filtering, and more granular tuning, OpenSearch-based architectures are usually stronger candidates.
LakeStack architecture
LakeStack becomes the governance layer that makes Bedrock production-ready in enterprise settings. It organizes data in Amazon S3 with domain-oriented structures, metadata tagging, access boundaries, and lineage-aware controls so the AI layer always sits on top of a managed foundation.
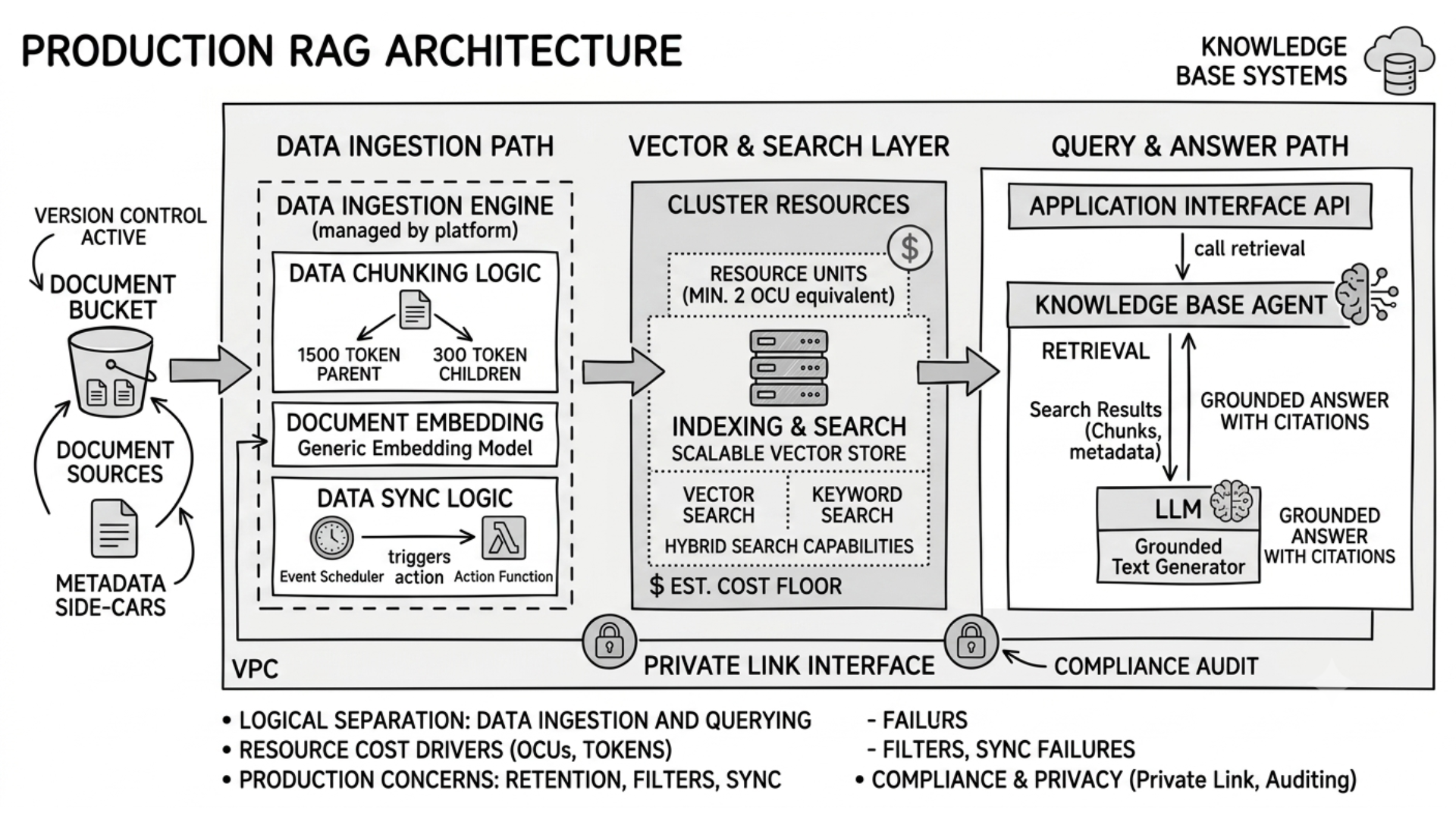
A practical LakeStack + Bedrock architecture has five layers. First is ingestion and governance, where data lands in S3 and is classified, tagged, and access-controlled. Second is embedding and indexing, where Bedrock Knowledge Bases chunks the content, creates embeddings, and stores them in the selected vector backend. Third is retrieval, where the query is embedded and compared against the index using semantic similarity and optional filters. Fourth is generation, where the selected foundation model produces a response grounded in retrieved context. Fifth is observability, where logging, monitoring, and quality checks keep the pipeline trustworthy.
This layered approach is what turns a demo into a durable enterprise capability. It allows different teams to own different parts of the stack while preserving a common governance model and a consistent operating standard.
Bedrock knowledge bases
Amazon Bedrock Knowledge Bases is the managed service that ties retrieval and generation together. It can connect to unstructured or structured data sources, sync data into a chosen vector store, and support both retrieval-only and retrieve-and-generate workflows.
The Retrieve API queries a knowledge base and returns relevant source information, while RetrieveAndGenerate can fetch the context and produce an answer in one flow. This makes it simpler for application teams to deliver RAG features without building a custom retrieval orchestration layer from scratch.
Bedrock also supports chunking strategies that matter in real-world use. Semantic chunking preserves meaning better for many documents, while hierarchical approaches can help when content has a nested structure such as policies, manuals, or technical documentation. For enterprise content, chunking quality often has a bigger impact on answer relevance than the model choice itself.
Real-time freshness
One of the hardest problems in production RAG is freshness. Even a well-designed index becomes less useful if it is not updated when source data changes. A stale answer can be worse than no answer at all because it creates false confidence.
LakeStack and Bedrock can address freshness through event-driven updates, incremental sync, and CDC-style ingestion patterns. When new files arrive in governed S3 locations, Lambda or EventBridge can trigger re-embedding jobs. Bedrock knowledge bases also support targeted sync behavior so teams do not need to rebuild indexes from scratch every time content changes.
For operational systems, a hybrid strategy is often best. Stable knowledge can stay in the vector store, while the latest transactional data is fetched directly from systems like DynamoDB or other operational stores during request time. That combination gives users both semantic search and current-state accuracy.
Production implementation
A typical production implementation starts with the LakeStack data foundation. Documents, PDFs, knowledge articles, and other content are ingested into S3 using domain-specific folders, metadata tags, and access policies that match business ownership. That structure makes downstream retrieval simpler and safer.
Next, a Bedrock knowledge base is configured to point at the S3 source. The team chooses an embeddings model such as Amazon Titan Text Embeddings V2 and selects a vector backend such as OpenSearch Serverless, Aurora PostgreSQL, or S3 Vectors based on workload needs. Then the ingestion job is run to chunk, embed, and index the content.
The application layer usually uses RetrieveAndGenerate for simplicity, but some teams separate retrieval and generation for finer control over prompt assembly, filters, ranking, and post-processing. Metadata filters are especially important in enterprise deployments because they preserve user-specific access boundaries across the retrieval path.
Production hardening
A demo becomes production-ready only after the reliability, cost, and security layers are in place. Retrieval quality should be evaluated with tests that measure recall, precision, citation quality, and answer completeness. Frameworks such as RAGAS are commonly used to quantify these dimensions, though the broader principle is to evaluate retrieval, not just generation.
Cost management also matters. OpenSearch Serverless is operationally convenient, but teams should watch compute usage carefully and align backend choice with traffic patterns. For lower-volume or cost-sensitive workloads, S3 Vectors may be a compelling alternative backend in Bedrock-supported workflows.
Security must extend from storage to retrieval to response generation. LakeStack access controls, S3 Access Grants, IAM integration, Bedrock guardrails, and logging should work together as one policy plane rather than separate layers of control. Monitoring should cover ingestion status, query latency, retrieval confidence, and user feedback so issues are visible before they affect business users.
Monitoring and observability
Observability is not optional in enterprise AI. Amazon Bedrock supports knowledge base logging through CloudWatch Logs, Amazon S3, or Amazon Data Firehose, which gives teams a way to track ingestion and delivery behavior. That is useful for spotting failures, stale content, permission problems, and indexing delays.
Guardrails metrics can also be monitored in CloudWatch, which helps teams track safety-related behavior as part of the operating model. Combined with retrieval logs and source citations, this creates the audit trail enterprises need when deploying AI in regulated environments.
LakeStack adds another important dimension by tying these signals back to governed data domains. That means teams can understand not only whether the model responded correctly, but also whether the right content was available, whether access rules were enforced, and whether the source data pipeline stayed healthy.
Business value
The business case for governed RAG is straightforward. Employees spend less time searching and validating information, support teams answer questions faster, and decision-makers receive responses grounded in authoritative data rather than generic model output. That improves productivity while reducing risk.
The biggest ROI often comes from reducing “information friction.” Instead of manually searching across systems, people ask a question and get a response with citations. Instead of maintaining a brittle rules-based knowledge portal, teams operate a dynamic retrieval layer that reflects current business content. Instead of worrying about which documents were used, the organization has a logged, governed pipeline that can be audited.
For enterprises already investing in data governance, the RAG use case becomes especially attractive because the same controls that protect analytics can also protect generative AI. That creates a direct bridge between data architecture and AI value realization.
Looking ahead
The RAG landscape is still evolving quickly. We are seeing stronger multimodal support, better chunking methods, more flexible retrieval backends, and deeper integration with agents and workflows. Enterprises are also beginning to combine vector search with knowledge graphs, memory layers, and structured reasoning systems for more advanced decision support.
LakeStack + Amazon Bedrock is well positioned for that future because it preserves the fundamentals: governed storage, policy-aware access, controlled retrieval, and scalable model orchestration. That means new capabilities can be added without rebuilding the enterprise database layer every time the AI stack changes.
Conclusion
LakeStack and Amazon Bedrock provide a practical, enterprise-grade way to build production RAG pipelines on governed data. The combination supports semantic search, real-time freshness, compliant access control, and observability while giving teams flexibility in choosing the right AWS vector backend for the workload.
For organizations that want to move beyond AI pilots, this architecture delivers a durable path forward. It connects governed data to trustworthy generative experiences, which is exactly what enterprise AI needs to scale with confidence.
.png)


